Flink认为Batch是Streaming的一个特例,而window就是从Streaming到Batch的一个桥梁,window提供了一种处理无界数据的手段。
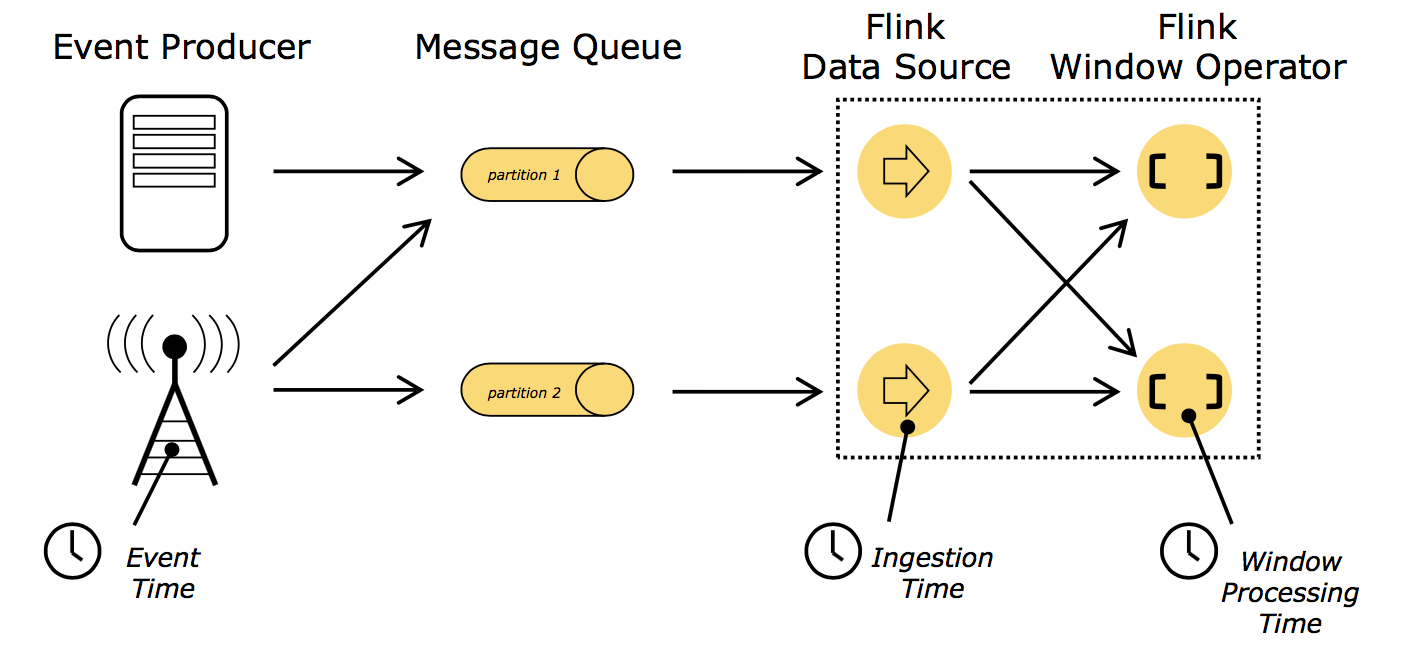
Flink的时间
Flink有三种时间概念,分别是:
- event time, 事件时间, 事件发生时的时间
- ingestion time, 摄取时间, 事件进入流处理系统的时间
- processing time, 处理时间, 消息被计算处理的时间
窗口的生命周期
窗口的生命周期,就是创建和销毁。
窗口的开始时间和结束时间是基于自然时间创建的,比如指定一个5s的窗口,那么1分钟内就会创建12个窗口。
什么时候窗口会被创建?
当第一个元素进入到窗口开始时间的时候,这个窗口就被创建了。
什么时候窗口会被销毁?
当时间(ProcessTime、EventTime或者 IngestionTime)越过了窗口的结束时间,再加上用户自定义的窗口延迟时间(allowed lateness),窗口就会被销毁。
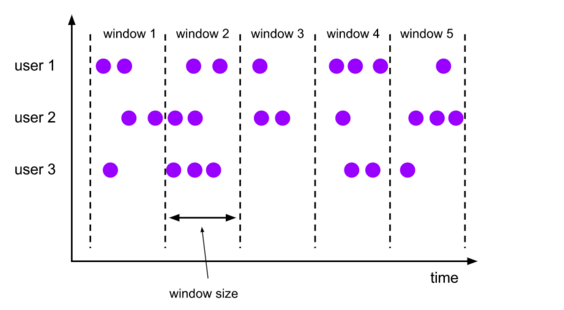
窗口示例
假设我们定义了一个基于事件时间的窗口,长度是5分钟,并且允许有1分钟的延迟。
当第一个元素包含了一个12:00的事件时间进来时,Flink会创建一个12:00 到 12:05 的窗口;在水位到 12:06 的时候,会销毁这个窗口。
每个窗口都会绑定一个触发器和一个执行函数。触发器定义了何时会触发窗口的执行函数的计算
,比如在窗口元素数量大于等于4的时候,或者水位经过了窗口结束时间的时候。
另外,每个窗口可以指定 驱逐器(Evictor),它的作用是在触发器触发后,执行函数执行前,移除一些元素。
窗口的类别和选择
窗口按照驱动方式可以粗略地分为Time Window和Count Window。
- 时间驱动的(Time Window,例如:每30秒钟)
- 数据驱动的(Count Window,例如:每100个元素)
在定义窗口之前,首先要指定你的流是否应该被分区,使用 keyBy(…) 后,相同的 key 会被划分到不同的流里面,每个流可以被一个单独的 task 处理。如果 不使用 keyBy ,所有数据会被划分到一个窗口里,只有一个task处理,并行度是1.
Time Window
Flink预定义了很多窗口类型,可以满足大多数场景的使用: tumbling windows(翻滚窗口), sliding windows(滑动窗口), session windows(会话窗口)。
所有内置的窗口(除了全局窗口)都是基于时间(ProcessTime或 EventTime)的。
- Tumbling Windows
翻滚窗口有一个固定的长度,并且不会重复。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// 例子1:tumbling event-time windows
// 定义一个数据流
val input: DataStream[T] = ...
// 这里的 key selector,如果是元组的化,可以使用_._1,如果是case class 可以使用字段名来指定
input
.keyBy(<key selector>)
// 指定了一个TumblingEventTimeWindows,窗口大小为5分钟
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 窗口的操作
.<windowed transformation>(<window function>)
// 例子2:tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// 例子3:daily tumbling event-time windows offset by -8 hours.
//
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
|
在例子3中,TumblingEventTimeWindows.of 指定了第二个参数 offset,它的作用是改变窗口的时间。
如果我们指定了一个15分钟的窗口,那么每个小时内,每个窗口的开始时间和结束时间为:
[00:00,00:15)
[00:15,00:30)
[00:30,00:45)
[00:45,01:00)
如果我们指定了一个5分钟的offset,那么每个窗口的开始时间和结束时间为:
[00:05,00:20)
[00:20,00:35)
[00:35,00:50)
[00:50,01:05)
一个实际的应用场景是,我们可以使用 offset 使我们的时区以0时区为准。比如我们生活在中国,时区是
UTC+08:00,可以指定一个 Time.hour(-8),使时间以0时区为准。
- Slidding Windows
滑动窗口指定了两个参数,第一个参数是窗口大小,第二个参数控制了新的窗口开始的频率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
val input: DataStream[T] = ...
// 例子1:sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 例子2:sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 例子3,sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
|
- Session Windows
会话窗口根据会话的间隔来把数据分配到不同的窗口。会话窗口不重叠,没有固定的开始时间和结束时间。
比如音乐 app 听歌的场景,我们想统计一个用户在一个独立的 session 中听了多久的歌曲(如果超过15分钟没听歌,那么就是一个新的 session 了)
Count Windows
- Tumbling Windows
1
2
3
4
5
6
7
8
9
10
|
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the carCnt sum
.sum(1)
|
- Sliding Window
每10个元素统计过去100个元素的数量之和。
1
2
3
4
5
|
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)
|
Advanced Windows (自定义窗口)
自定义的窗口需要指定3个function。
- Window Assigner:用来决定某个元素被分配到哪个/哪些窗口中去。
- Trigger:触发器。决定了一个窗口何时能够被计算或清除,每个窗口都会拥有一个自己的Trigger。
- Evictor:可以译为“驱逐者”。在Trigger触发之后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
- Window Assigner, 负责将元素分配到不同的window。
1
2
3
|
// create windowed stream using a WindowAssigner
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed
.window(myAssigner: WindowAssigner[IN, WINDOW])
|
WindowAPI提供了自定义的WindowAssigner接口,我们可以实现WindowAssigner的public abstract Collection assignWindows(T element, long timestamp)方法。同时,对于基于Count的window而言,默认采用了GlobalWindow的window assigner,例如:
1
|
keyValue.window(GlobalWindows.create())
|
全局 window 把所有相同 key 的数据,放到一个 window 来,它没有自然的窗口结束时间,所以我们需要自己指定触发器。
1
2
3
4
5
6
|
val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>)
|
- Trigger:触发器。决定了一个窗口何时能够被计算或清除,每个窗口都会拥有一个自己的Trigger。
我们可以复写一个trigger方法来替换WindowAssigner中的trigger,例如:
1
2
3
|
// override the default trigger of the WindowAssigner
windowed = windowed
.trigger(myTrigger: Trigger[IN, WINDOW])
|
对于CountWindow,我们可以直接使用已经定义好的Trigger:CountTrigger
1
|
trigger(CountTrigger.of(2))
|
- Evictor(可选),驱逐者,在Trigger触发之后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
1
2
3
|
// specify an optional evictor
windowed = windowed
.evictor(myEvictor: Evictor[IN, WINDOW])
|
- 示例
最简单的情况,如果业务不是特别复杂,仅仅是基于Time和Count,我们其实可以用系统定义好的WindowAssigner以及Trigger和Evictor来实现不同的组合:
例如:基于Event Time,每5秒内的数据为界,以每秒的滑动窗口速度进行operator操作,但是,当且仅当5秒内的元素数达到100时,才触发窗口,触发时保留上个窗口的10个元素。
1
2
3
4
|
keyedStream
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(1))
.trigger(CountTrigger.of(100))
.evictor(CountEvictor.of(10));
|
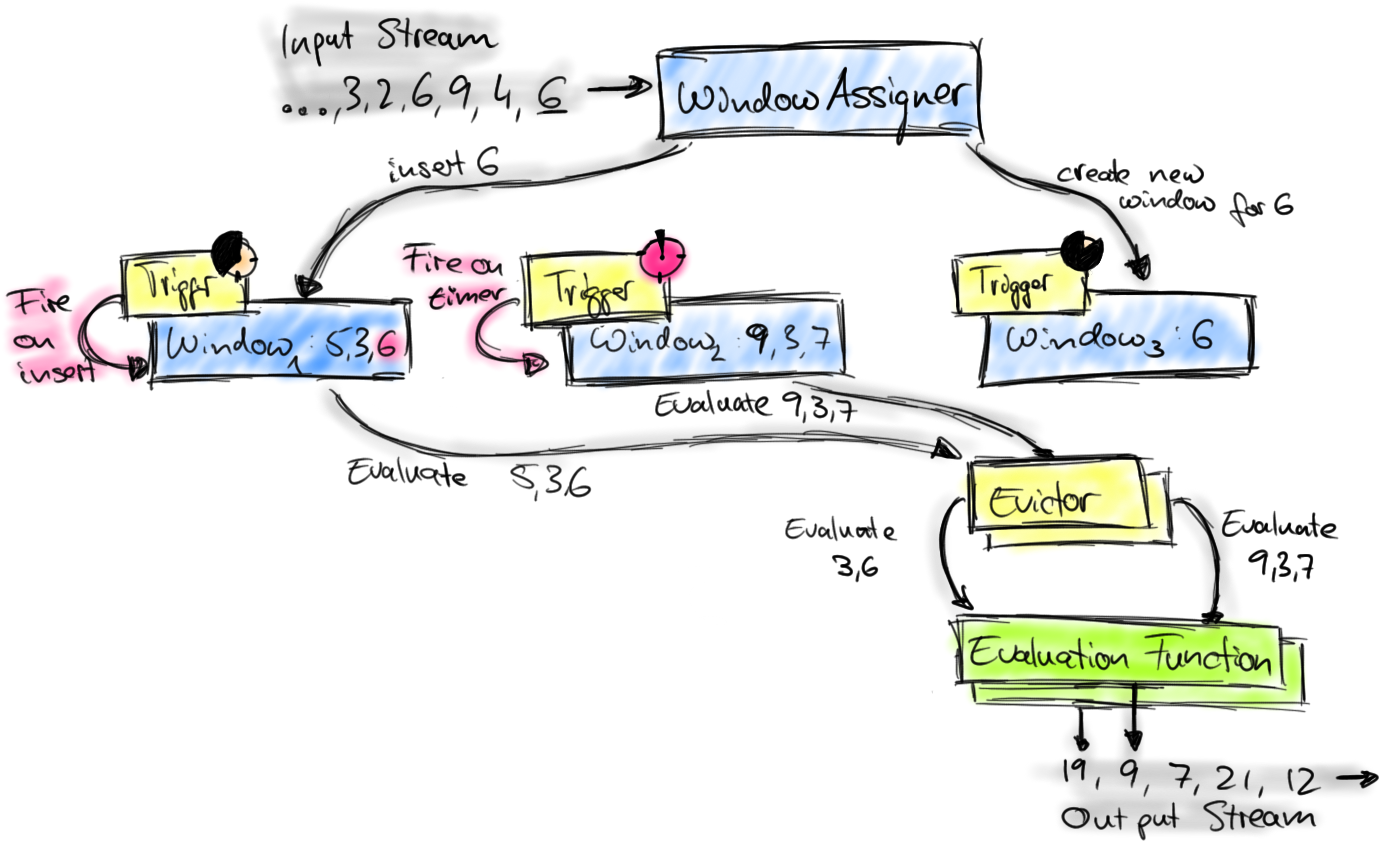
Flink窗口原理
Flink的窗口机制及各组件之间的分工如图所示。
-
首先上图中的组件都位于一个算子(window operator)中,数据流源源不断地进入算子,每一个到达的元素都会被交给 WindowAssigner。WindowAssigner 会决定元素被放到哪个或哪些窗口(window),可能会创建新窗口。因为一个元素可以被放入多个窗口中,所以同时存在多个窗口是可能的。注意,Window本身只是一个ID标识符,其内部可能存储了一些元数据,如TimeWindow中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,key为Window,value为元素集合(或聚合值)。为了保证窗口的容错性,该实现依赖了 Flink 的 State 机制。
-
每一个窗口都拥有一个属于自己的 Trigger,Trigger上会有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素加入到该窗口,或者之前注册的定时器超时了,那么Trigger都会被调用。Trigger的返回结果可以是 continue(不做任何操作),fire(处理窗口数据),purge(移除窗口和窗口中的数据),或者 fire + purge。一个Trigger的调用结果只是fire的话,那么会计算窗口并保留窗口原样,也就是说窗口中的数据仍然保留不变,等待下次Trigger fire的时候再次执行计算。一个窗口可以被重复计算多次知道它被 purge 了。在purge之前,窗口会一直占用着内存。
-
当Trigger fire了,窗口中的元素集合就会交给Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有 Evictor 的话,窗口中的所有元素会一起交给函数进行计算。
-
计算函数收到了窗口的元素(可能经过了 Evictor 的过滤),并计算出窗口的结果值,并发送给下游。窗口的结果值可以是一个也可以是多个。DataStream API 上可以接收不同类型的计算函数,包括预定义的sum(),min(),max(),还有 ReduceFunction,FoldFunction,还有WindowFunction。WindowFunction 是最通用的计算函数,其他的预定义的函数基本都是基于该函数实现的。
Flink 对于一些聚合类的窗口计算(如sum,min)做了优化,因为聚合类的计算不需要将窗口中的所有数据都保存下来,只需要保存一个result值就可以了。每个进入窗口的元素都会执行一次聚合函数并修改result值。这样可以大大降低内存的消耗并提升性能。但是如果用户定义了 Evictor,则不会启用对聚合窗口的优化,因为 Evictor 需要遍历窗口中的所有元素,必须要将窗口中所有元素都存下来。
Flink window示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
package org.apache.flink.streaming.scala.examples.socket
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object SocketWindowWordCount {
/** Main program method */
def main(args: Array[String]) : Unit = {
// the host and the port to connect to
var hostname: String = "localhost"
var port: Int = 0
try {
val params = ParameterTool.fromArgs(args)
hostname = if (params.has("hostname")) params.get("hostname") else "localhost"
port = params.getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please run 'SocketWindowWordCount " +
"--hostname <hostname> --port <port>', where hostname (localhost by default) and port " +
"is the address of the text server")
System.err.println("To start a simple text server, run 'netcat -l <port>' " +
"and type the input text into the command line")
return
}
}
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// get input data by connecting to the socket
val text: DataStream[String] = env.socketTextStream(hostname, port, '\n')
// parse the data, group it, window it, and aggregate the counts
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy(_.word)
.timeWindow(Time.seconds(5))
.sum("count")
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
/** Data type for words with count */
case class WordWithCount(word: String, count: Long)
}
|
参考