双流JOIN与传统数据库表JOIN的区别
传统数据库表的JOIN是两张静态表的数据联接,在流上面是动态表,双流JOIN的数据不断流入与传统数据库表的JOIN有如下3个核心区别:
-
左右两边的数据集合无穷 - 传统数据库左右两个表的数据集合是有限的,双流JOIN的数据会源源不断的流入。
-
JOIN的结果不断产生/更新 - 传统数据库表JOIN是一次执行产生最终结果后退出,双流JOIN会持续不断的产生新的结果。
-
查询计算的双边驱动 - 双流JOIN由于左右两边的流的速度不一样,会导致左边数据到来的时候右边数据还没有到来,或者右边数据到来的时候左边数据没有到来,所以在实现中要将左右两边的流数据进行保存,以保证JOIN的语义。
数据shuffle
分布式流计算所有数据会进行Shuffle,怎么才能保障左右两边流的要JOIN的数据会在相同的节点进行处理呢?在双流JOIN的场景,我们会利用JOIN中ON的联接key进行partition,确保两个流相同的联接key会在同一个节点处理,这个在flink的源码中有说明。
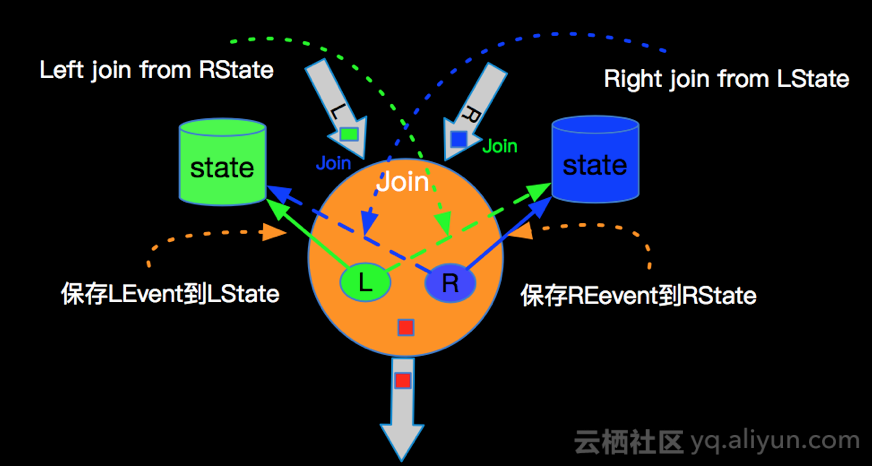
数据的保存
不论是INNER JOIN还是OUTER JOIN 都需要对左右两边的流的数据进行保存,JOIN算子会开辟左右两个State进行数据存储,左右两边的数据到来时候,进行如下操作:
-
LeftEvent到来存储到LState,RightEvent到来的时候存储到RState;
-
LeftEvent会去RightState进行JOIN,并发出所有JOIN之后的Event到下游;
-
RightEvent会去LeftState进行JOIN,并发出所有JOIN之后的Event到下游。
算子实现
Flink DataStream API为用户提供了3个算子来实现双流Join,分别是:
-
join()
-
coGroup()
-
intervalJoin()
Join
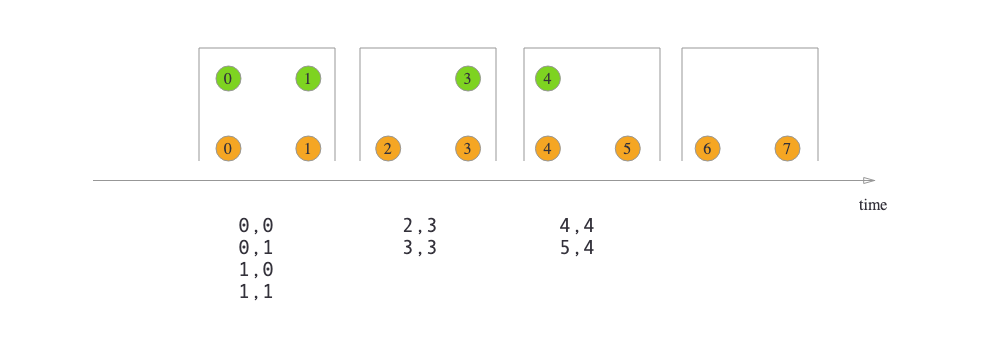
join()算子提供的语义为"Window join",即按照指定字段和(滚动/滑动/会话)窗口进行inner join,支持处理时间和事件时间两种时间特征。
以下示例以10秒滚动窗口,将两个流通过商品ID关联,取得订单流中的售价相关字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
clickRecordStream
.join(orderRecordStream)
.where(record -> record.getMerchandiseId())
.equalTo(record -> record.getMerchandiseId())
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply(new JoinFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, String>() {
@Override
public String join(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord) throws Exception {
return StringUtils.join(Arrays.asList(
accessRecord.getMerchandiseId(),
orderRecord.getPrice(),
orderRecord.getCouponMoney(),
orderRecord.getRebateAmount()
), '\t');
}
})
.print().setParallelism(1);
|
coGroup
join算子只能实现inner join,如何实现left/right outer join呢?答案就是利用coGroup()算子。它的调用方式类似于join()算子,也需要开窗,但是CoGroupFunction比JoinFunction更加灵活,可以按照用户指定的逻辑匹配左流和/或右流的数据并输出。
以下的例子就实现了点击流left join订单流的功能,是很朴素的nested loop join思想(二重循环)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
clickRecordStream
.coGroup(orderRecordStream)
.where(record -> record.getMerchandiseId())
.equalTo(record -> record.getMerchandiseId())
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply(new CoGroupFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, Tuple2<String, Long>>() {
@Override
public void coGroup(Iterable<AnalyticsAccessLogRecord> accessRecords, Iterable<OrderDoneLogRecord> orderRecords, Collector<Tuple2<String, Long>> collector) throws Exception {
for (AnalyticsAccessLogRecord accessRecord : accessRecords) {
boolean isMatched = false;
for (OrderDoneLogRecord orderRecord : orderRecords) {
// 右流中有对应的记录
collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), orderRecord.getPrice()));
isMatched = true;
}
if (!isMatched) {
// 右流中没有对应的记录
collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), null));
}
}
}
})
.print().setParallelism(1);
|
intervalJoin
join()和coGroup()都是基于窗口做关联的。但是在某些情况下,两条流的数据步调未必一致。例如,订单流的数据有可能在点击流的购买动作发生之后很久才被写入,如果用窗口来圈定,很容易join不上。所以Flink又提供了"Interval join"的语义,按照指定字段以及右流相对左流偏移的时间区间进行关联,即:
1
|
right.timestamp ∈ [left.timestamp + lowerBound; left.timestamp + upperBound]
|
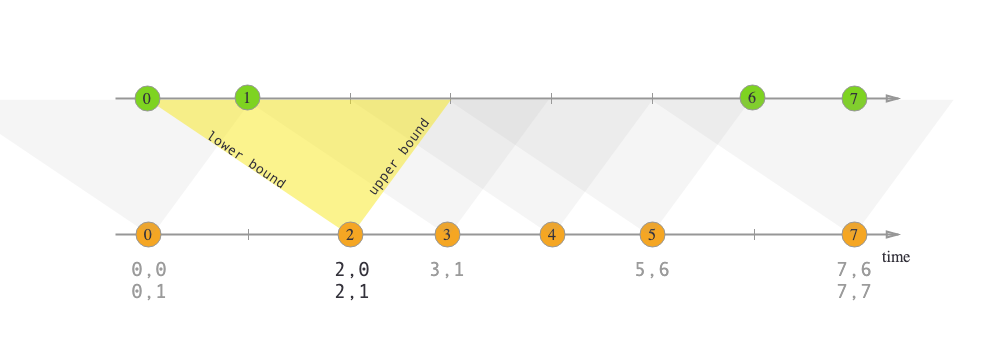
interval join也是inner join,虽然不需要开窗,但是需要用户指定偏移区间的上下界,并且只支持事件时间。
示例代码如下。注意在运行之前,需要分别在两个流上应用assignTimestampsAndWatermarks()方法获取事件时间戳和水印。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
clickRecordStream
.keyBy(record -> record.getMerchandiseId())
.intervalJoin(orderRecordStream.keyBy(record -> record.getMerchandiseId()))
.between(Time.seconds(-30), Time.seconds(30))
.process(new ProcessJoinFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, String>() {
@Override
public void processElement(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord, Context context, Collector<String> collector) throws Exception {
collector.collect(StringUtils.join(Arrays.asList(
accessRecord.getMerchandiseId(),
orderRecord.getPrice(),
orderRecord.getCouponMoney(),
orderRecord.getRebateAmount()
), '\t'));
}
})
.print().setParallelism(1);
|
由上可见,interval join与window join不同,是两个KeyedStream之上的操作,并且需要调用between()方法指定偏移区间的上下界。如果想令上下界是开区间,可以调用upperBoundExclusive()/lowerBoundExclusive()方法。
参考