Flink Checkpoint机制
文章目录
基于分布式快照的Checkpoint机制是Flink的容错机制的一大亮点,Flink可以通过Checkpoint实现exactly-once保证。
Flink Checkpoin简介
基于分布式快照的Checkpoint机制是Flink的容错机制的一大亮点,Flink可以通过Checkpoint实现exactly-once保证。Checkpoint可以保证应用程序出错时的容错处理,通过对程序的状态(一般指键值状态或者算子状态)进行快照,当应用程序出错时,可以通过获取上一次Checkpoint生成的快照,重放输入流和算子的状态,恢复到故障之前的状态。
Flink Checkpoint过程
启动checkpoint
想要使用Flink Checkpoint功能,首先是要在实时任务开启Checkpoint,Flink默认关闭Checkpoint。
|
|
checkpoint原理
Flink Job中需要容错的主要是两类对象: function和operator,state一般是指一个具体的taks/operator的状态,而checkpoint则表示一个Flink Job在某个时刻的一份全局状态快照,包含了所有task/operator的状态(两类状态keyed state 和 operator state)。
Flink分布式快照的核心概念之一是数据栅栏(Barrier),这些barrier被插入数据流中,作为数据流的一部分和数据一起往下流动,数据流严格有序,barrier不会干扰正常的数据,非常轻量。一个barrier把数据流分割成两部分,一部分进入当前快照,另一部分进入下一个快照,每个barrier都有快照id,并且barrier之前的数据都进入此快照。多个不同快照的多个barrier会在流中同时出现,即多个快照可能同时创建。
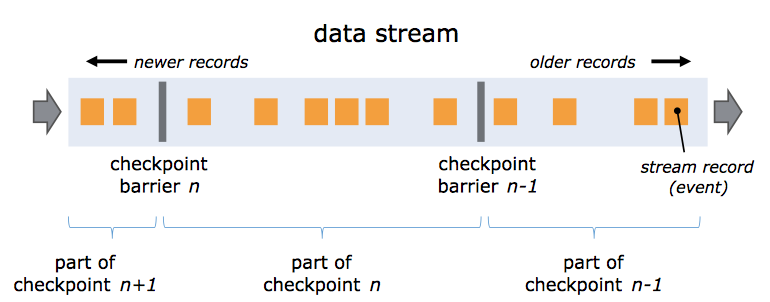
barrier在数据源端插入,当快照n的barrier插入后,系统会记录当前快照位置值,然后barrier继续往下流动,当一个算子从其输入流接收到所有的标识快照n的barrier时,它会向其他所有输出流发射一个标识快照n的barrier n。当sink端从其他输入流接收到所有的barrier n时,它就向CheckpointCoordinator确认快照n已完成,当所有的sink端确认了这个快照,快照就被标识为完成。
当一个算子接收超过一个输入流时,需要基于barrier对齐。
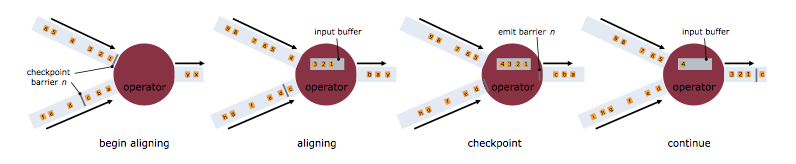
处理过程如下:
- 算子收到某个输入流的barrier n后,就不能继续处理此数据流后续的数据,直到该算子接收到其余流的barrier n。否则会将属于snapshot n的数据和snapshot n+1的搞混。
- barrier n所属的数据流先不做处理,从这些数据流中接收的数据被放入接收缓存。
- 当从最后一个流中提取到barrier n时,该算子会发射出所有等待向后发送的数据,然后发射snapshot n对应的barrier n
- 经过以上步骤,算子恢复所有输入流数据的处理,优先处理输入缓存中的数据。
checkpoint的过程
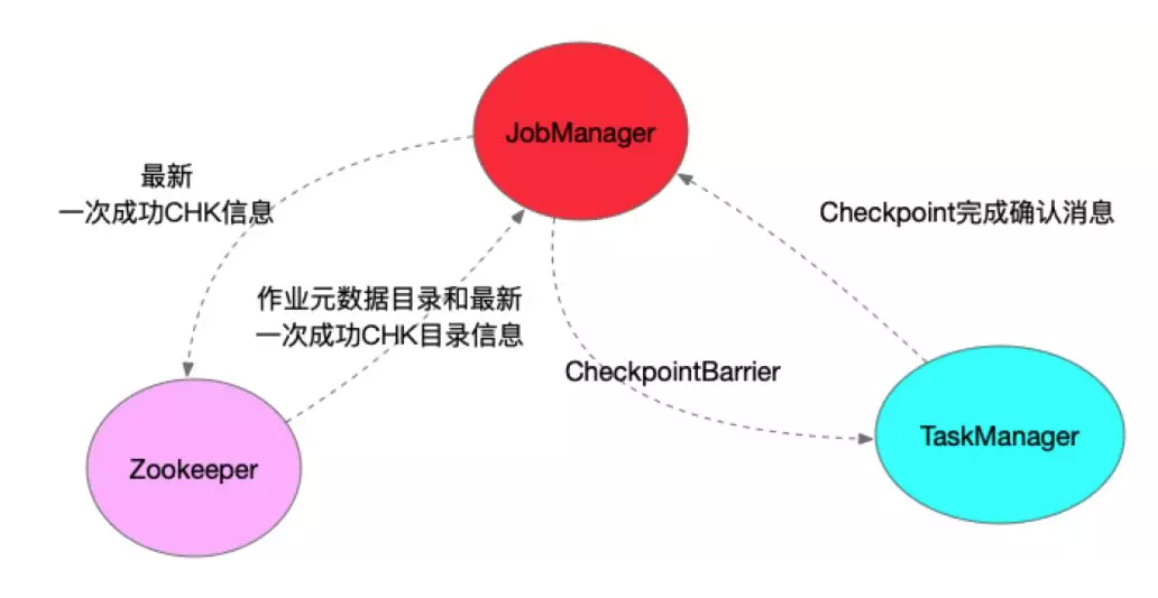
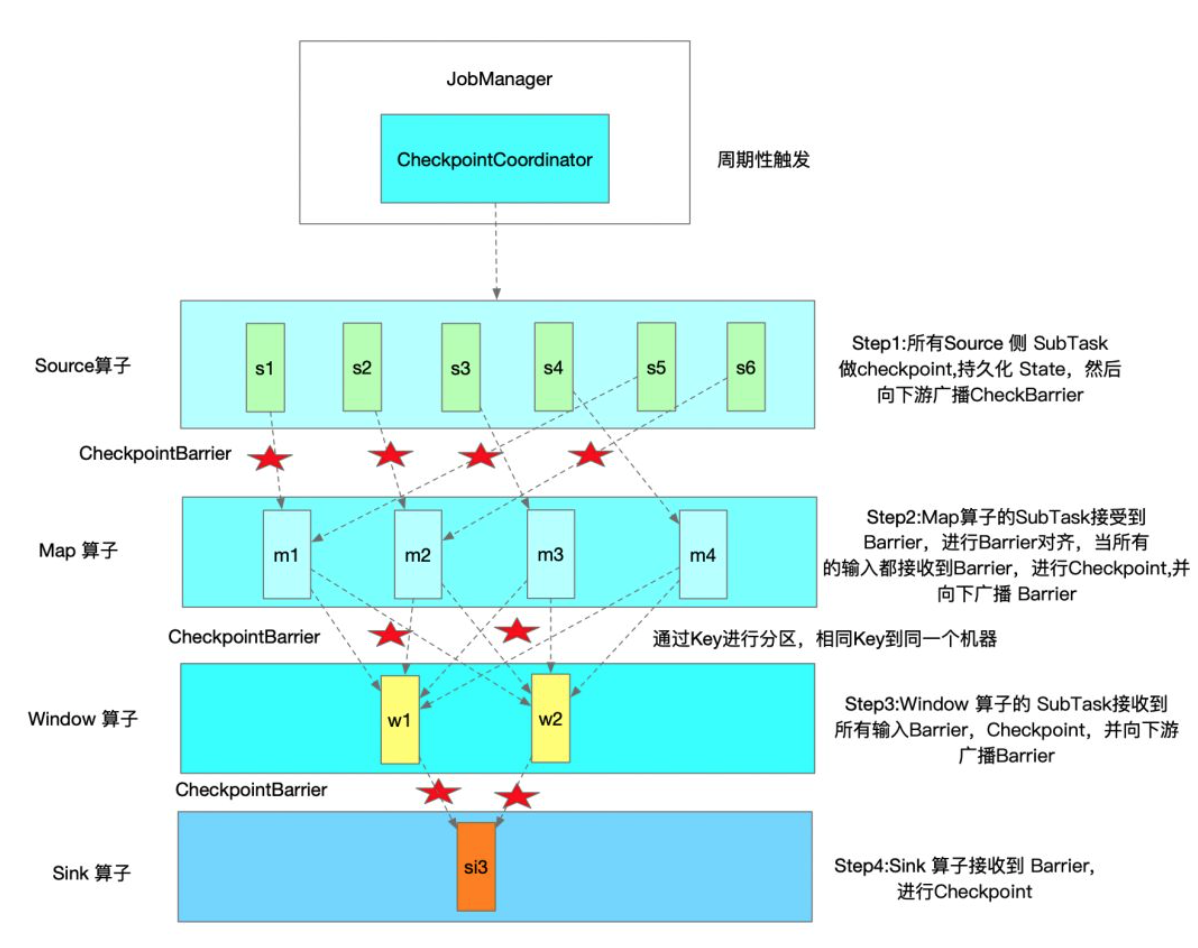
Flink 实时任务一次 Checkpoint 的参与者主要包括三块:JobManager、TaskManager以及 Zookeeper。JobManager 定时会触发执行 Checkpoint,具体则是在 JobManager 中运行的 CheckpointCoordinator 中触发所有 Source 的 SubTask 向下游广播 CheckpointBarrier。
TaskManager 收到 CheckpointBarrier 后,根据 Checkpoint 的语义,决定是否在进行 CheckpointBarrier 对齐时,缓冲后续的数据记录,当收到所有上游输入的 CheckpointBarrier 后,开始做 Checkpoint。TaskManager Checkpoint 完成后,会向 JobManager 发送确认完成的消息。只有当所有 Sink 算子完成 Checkpoint 且发送确认消息后,该次 Checkpoint 才算完成。
在高可用模式下,ZooKeeper 主要存储最新一次 Checkpoint 成功的目录,当Flink 任务容错恢复时,会从最新成功的 Checkpoint 恢复。Zookeeper 同时也存储着 Flink 作业的元数据信息。比如在高可用模式下,Flink 会将 JobGraph 以及相关 Jar 包存储在 HDFS 上面,Zookeeper 记录着该信息。再次容错重启时,读取这些信息,进行任务启动。
下图是一次Flink Checkpoint实例流程示意图:
Flink Checkpoint 语义
Flink Checkpoint 支持两种语义:Exactly_Once 和 At_least_Once,默认的 Checkpoint 语义是 Exactly_Once。Exactly_Once 和 At_Least_Once 具体在底层实现大致相同,具体差异表现在 CheckpointBarrier 对齐方式的处理。
-
如果是 Exactly_Once 模式,某个算子的 Task 有多个输入通道时,当其中一个输入通道收到 CheckpointBarrier 时,Flink Task 会阻塞该通道,其不会处理该通道后续数据,但是会将这些数据缓存起来,一旦完成了所有输入通道的 CheckpointBarrier 对齐,才会继续对这些数据进行消费处理。
-
对于 At_least_Once,同样针对某个算子的 Task 有多个输入通道的情况下,当某个输入通道接收到 CheckpointBarrier 时,它不同于 Exactly Once,即使没有完成所有输入通道 CheckpointBarrier 对齐,At Least Once 也会继续处理后续接收到的数据。所以使用 At Least Once 不能保证数据对于状态计算只有一次的计算影响。
Flink Checkpoint 和 Savepoint的区别
Flink Savepoint的底层原理和Flink Checkpoint几乎一致,都是用来保存Flink作业内部状态的快照机制,只有一些小的不同,不同点如下:
- checkpoint是定期自动触发的,会过期;而savepoint需要手动触发,并且不会过期。
- checkpoint用于Flink任务故障时自动重启任务,而savepoint通常存储在外部,通常会启动一个“新”的任务。Savepoint使用的场景有:
- bug fixing
- flink版本升级
- A/B testing等
- 使用savepoint的前提
- 开始checkpoint
- 可重复使用的数据源(Kafka、文件系统)
- 所有保存的状态需要继承Flink的管理状态接口
- 合适的state backend配置
Flink checkpoint调优
- 当 Checkpoint 时间比设置的 Checkpoint 间隔时间要长时,可以设置 Checkpoint 间最小时间间隔。这样在上次 Checkpoint 完成时,不会立马进行下一次 Checkpoint,而是会等待一个最小时间间隔,之后再进行 Checkpoint。否则,每次 Checkpoint 完成时,就会立马开始下一次 Checkpoint,系统会有很多资源消耗 Checkpoint 方面,而真正任务计算的资源就会变少。
|
|
-
如果Flink状态很大,在进行恢复时,需要从远程存储上读取状态进行恢复,如果状态文件过大,此时可能导致任务恢复很慢,大量的时间浪费在网络传输方面。此时可以设置 Flink Task 本地状态恢复,任务状态本地恢复默认没有开启,可以设置参数 state.backend.local-recovery 值为 true 进行激活。 如果内存空间有限,不足以作为State的存储,则可以使用高效的外部存储介质,如RocksDB。
-
Checkpoint 保存数,Checkpoint 保存数默认是1,也就是只保存最新的 Checkpoint 的状态文件,当进行状态恢复时,如果最新的 Checkpoint 文件不可用时(比如 HDFS 文件所有副本都损坏或者其他原因),那么状态恢复就会失败,如果设置 Checkpoint 保存数 2,即使最新的Checkpoint恢复失败,那么Flink 会回滚到之前那一次 Checkpoint 的状态文件进行恢复。考虑到这种情况,用户可以增加 Checkpoint 保存数。
-
建议设置的 Checkpoint 的间隔时间最好大于 Checkpoint 的完成时间。
Checkpoint在新版本中的变化
Flink1.11引入非对齐的checkpoint(Unaligned Checkpoint),在Flink之前的版本,checkpoint的对齐操作会使先收到barrier的input channel后续到来的数据缓存起来,一直等到所有的input channel都接收到chechkpoint barrier并且checkpoint操作完毕后,才放开数据进入operator。这样虽然保证了exactly-once,但是显著的增加了延迟,降低了性能。如果再遇到数据反压,情况会更加糟糕。
Unaligned Checkpoint的引入解决了传统Aligned Checkpoint同时数据高反压的场景下,一条数据流延迟高会影响到另一个数据流的问题。Unaligned checkpoint改变了过去checkpoint的逻辑。主要有以下几点:
- 如果有一个input channel接收到barrier,开始checkpoint过程,并记录下checkpoint id。
- 在operator输出缓存头部(最先出缓存的位置)中插入一个新的checkpoint barrier,用于向下游广播。
- 从各个input channel读取数据buffer写入到checkpoint,直到读取到checkpoint id为先前记录的id的barrier。(1)中的input channel由于已经读取到barrier了,它之后的数据不会被记录到checkpoint中。
- Aligned checkpoint在所有input channel接收到barrier候触发,unaligned checkpoint在任何一个input channel接收到第一个barrier时触发。
- Unaligned checkpoint不会阻塞任何input channel。
以上步骤用Flink官网的图描述如下:
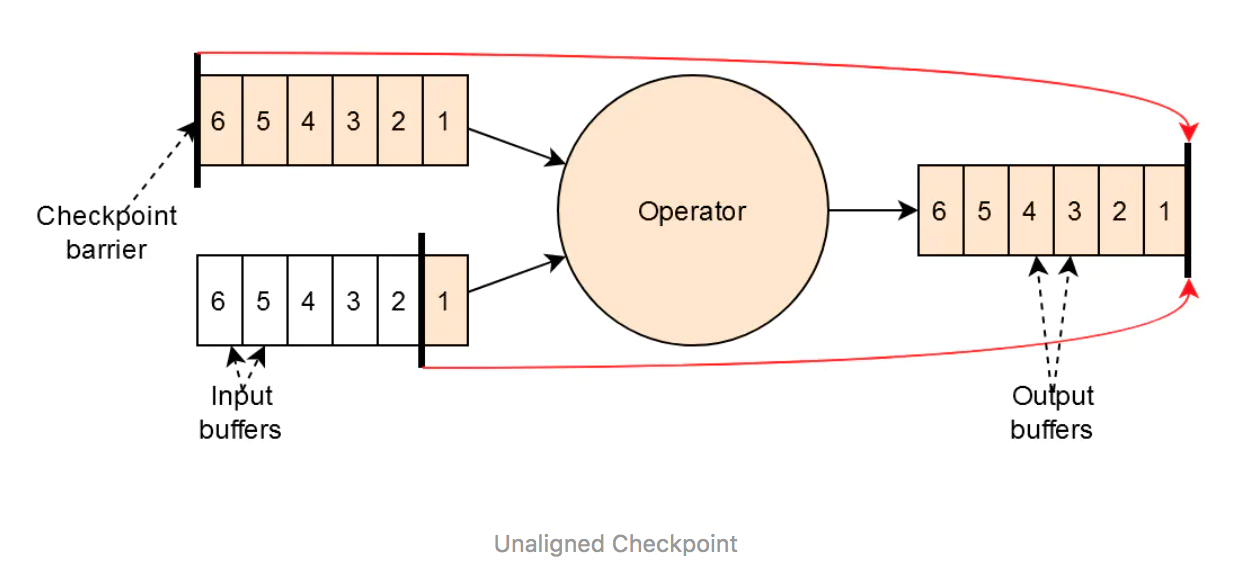 其中黄色部分的数据需要写入到checkpoint中,包含输入端所有channel的checkpoint barrier之后的数据buffer,operator内部的状态和输出端buffer。
其中黄色部分的数据需要写入到checkpoint中,包含输入端所有channel的checkpoint barrier之后的数据buffer,operator内部的状态和输出端buffer。
参考
文章作者 Hobbin
上次更新 2020-08-16 22:21:05