Flink状态管理
文章目录
Flink最区别于其他流式计算引擎的,其实就是状态管理。
1.什么是状态
在数据处理任务中,经常要对数据进行统计,如Sum、Count、Min、Max等,这些值是需要存储的。因为要不断更新,这些值或者变量就可以理解成一种状态。如果数据源是在读取Kafka、RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。
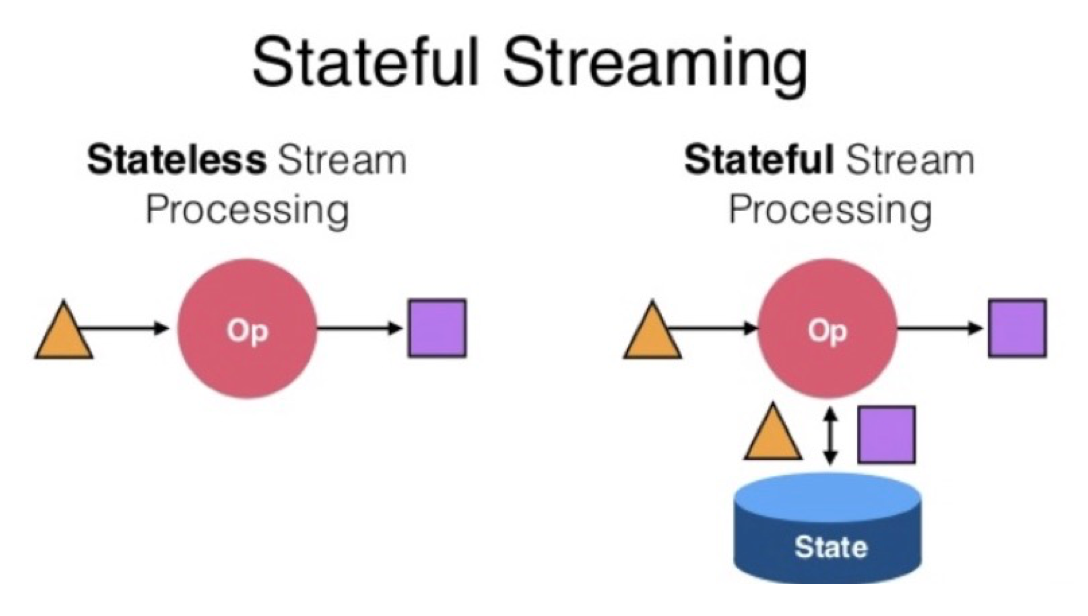
2.Flink状态管理
Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储到外部系统。这样做的好处是第一降低了计算引擎对外部系统的依赖以及部署,使运维更加简单。第二,对性能带来了极大的提升。如果通过外部去访问,如 Redis,HBase,它一定是通过网络及RPC。 如果访问Flink内部,它只需通过自身的进程去访问这些变量。
Flink内部提供了如下几种状态存储方式:
1)MemoryStateBackend
将内部的数据存储在Java堆里,kv状态或者window operator用hash table来保存values,triggers等。适合本地开发和调试,状态比较少的作业。
2)FsStateBackend
通过文件系统的URL来设置,比如"hdfs://namenode:40010/flink/checkpoints"或者"file:///data/flink/checkpoints"。保持数据在TaskManager的内存中,当做checkpointing的时候,会将状态快照写入文件,保存在文件系统或本地目录。少量的元数据会保存在JobManager的内存中。适用于状态比较大、窗口比较长、大的kv状态及需要做HA的场景。
3)RocksDBStateBackend
RocksDBStateBackend通过文件系统的URL来设置,例如"hdfs://namenode:40010/flink/checkpoints"或者"file:///data/flink/checkpoints"。保存数据在一个叫做RocksDB的数据库中,这个数据库保存在TaskManager的数据目录中。当做checkpoint时,整个数据库会被写入文件系统和目录。少量的元信息会保存在JobManager的内存中。适合非常大的状态、长窗口、大kv状态,需要HA的场景。RocksDBStateBackend是目前唯一支持incremental的checkpoints的策略。
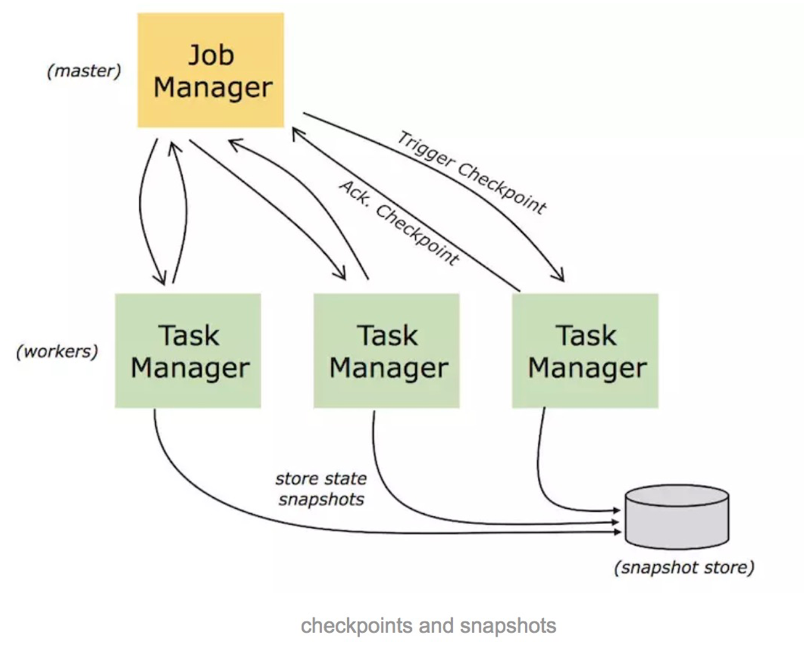
Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如 HDFS。这样的话,当 Flink 的任务出现任何故障时,它都会从最近的一次 Checkpoint 将整个流的状态进行恢复,然后继续运行它的流处理。对用户没有任何数据上的影响。
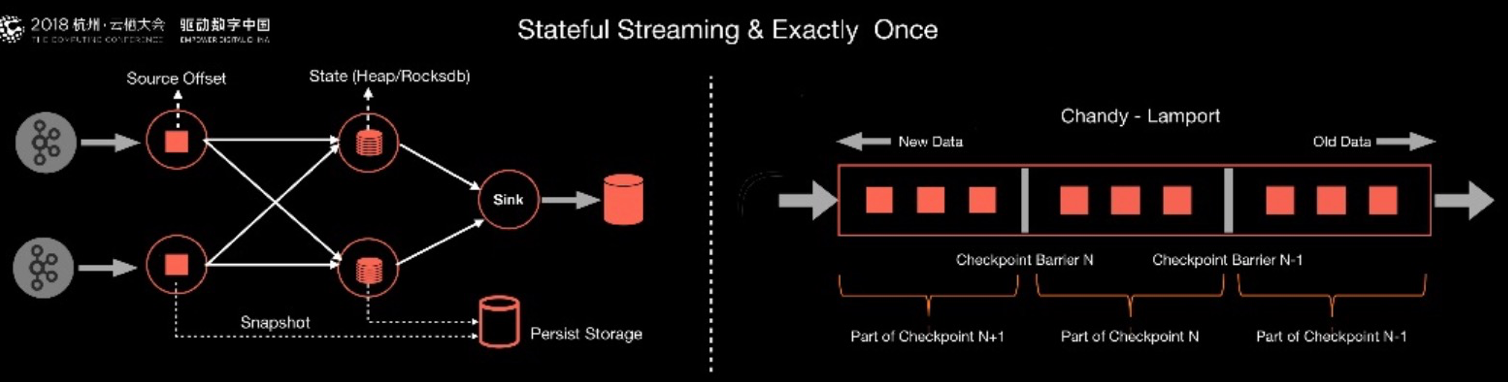
3.Flink是如何做到在checkpoint恢复过程中没有任何数据的丢失和数据冗余?保证精准计算的?
Flink利用了一套非常经典的Chandy-Lamport算法(一种分布式快照算法),其核心思想是:把这个流计算看成一个流式的拓扑,定期从这个拓扑的头部Source点开始插入特殊的Barriers,从上游开始不断地向下游广播这个Barriers。每个节点收到所有的Barriers,会将State做一次Snapshot,当每个节点都做完Snapshot后,整个拓扑就算完整做完了一次Checkpoint。接下来不管出现任何故障,都会从最近的Checkpoint进行恢复。Flink利用这套经典的算法,保证了强一致性语义。
4.Flink state的分类(来自官方文档)
Flink的state有两种,分别是Keyed State和Operator State。 两者可以以两种方式存在,分别是managed 和 raw。
其中Managed State是受Flink运行时环境控制的数据结构,内部hash tables, 或者 RocksDB, 比如"ValueState", “ListState”。Flink运行时环境对这些状态进行编码并写入到checkpoint中。
Raw State 保存在operator自己的数据结构中。推荐使用Managed State,因为当并发数变化后,Flink能够自动重新分布State,而且在内存管理方面更好。
1)Keyed State通常和一个keys相关,且只能用在keyedStream上的方法和操作上。 每一个keyed state逻辑上和唯一一个组合绑定,<parallel-operator-instance, key>,由于每个key属于唯一一个keyed oprator,因此也可以认为是 <oprator, key>。
2)Operator State, Operator State(非keyed State),每个操作状态和一个操作实例绑定。 Kafka connector是个很好的例子,每个Kafka消费者保存一个topic partitions的映射和offset作为他的Operator State。
5.参考
文章作者 Hobbin
上次更新 2020-07-15 22:12:09