Flink作业并行度配置
文章目录
Flink程序的并行执行
Flink程序的执行是并发和分布式的,在执行期间,一个流(stream)会有一个或者多个流分片(stream partition),且每个算子都有一个或者多个算子子任务(operator subtask)。算子子任务彼此之间是相互独立的,运行在不同的线程里,也可能是在不同的机器或者容器(containers)里。算子子任务的数量就是这个特定算子的并行度。同一个程序的不同算子可以有不同的并行度。

数据流可以通过两种方式在两个算子之间传递数据,一种是一对一(one-to-one)(或从头至尾(forwarding))的方式,另一种是重分配(redistributing)的方式。
- 一对一方式:意味着在两个算子中保持元素的分片和顺序。比如map()算子的subtask[1]会看到souce算子的subtask[1]生产的元素,且顺序和后者生产的顺序保持一致。
- 重新分配方式:每个算子子任务发送数据到不同目标子任务。比如上面的map()算子和keyBy()/window()算子,keyBy()/window()算子和sink算子。常见的会重新分配的算子有:keyBy()(通过对key进行hash,实现re-partition),broadcast(),rebalance()(随机re-partition)。在重新分配后,只有在一对发送、接收子任务内的元素才是有序的(比如map()的subtask[1]和KeyBy()/window()的subtask[2])。所以在这个例子中,并行机制保证每个key内部的顺序,但是不同key到达sink后聚合结果的顺序不能保证。
Flink Parallelism配置
任务(task)的并发度有不同层级的设置。优先级: 算子设置并行度 > env设置并行度 > 客户端设置并行度 > 系统设置并行度
- 算子设置并行度
每个算子(operator)、data source、data sink的并发可以通过调用它的setParallelism() 方法进行设置。
|
|
- env(执行环境)设置并行度
Flink程序运行在一个执行环境(execution environment)的上下文(context)里,执行环境可以指定所有算子、data source、data sink的默认并发度。通过调用setParallelism()进行设置。
算子层级的并行度设置会压盖执行环境的并行度设置。
|
|
- 客户端设置并行度
在提交Flink任务时,可以通过参数指定,通过-p参数设置。
|
|
在Client程序中设置:
|
|
- 系统设置并行度
修改./conf/flink-conf.yaml配置,配置项:parallelism.default, 默认是1。
Flink Slots的配置
Flink通过把程序切分到不同的子任务(subtask),并把这些子任务调度到执行slots上,实现程序的并行执行。TaskManager提供多个slots,slots决定了TaskManager的并发能力。slots的数量取决于TaskManager上CPU cores的数量。taskmanager.numberOfTaskSlots的值建议设置为TaskManager的可用CPU核数。Yarn session模式下通过—container 参数设置TaskManager的数量。 —container : Number of YARN container to allocate (=Number of Task Managers) 。
Yarn Single Job模式提交作业时并不像session模式能够指定拉起多少个TaskManager,TaskManager的数量是在提交作业时根据并发度动态计算。首先,根据设定的operator的最大并发度计算,例如,如果作业中operator的最大并发度为10,然后根据 Parallelism和numberOfTaskSlots为向YARN申请的TaskManager数。例如:如果算子中的最大Parallelism为10,numberOfTaskSlots为1,则TaskManager为10。如果算子中的最大Parallelism为10,numberOfTaskSlots为3,则TaskManager为4。

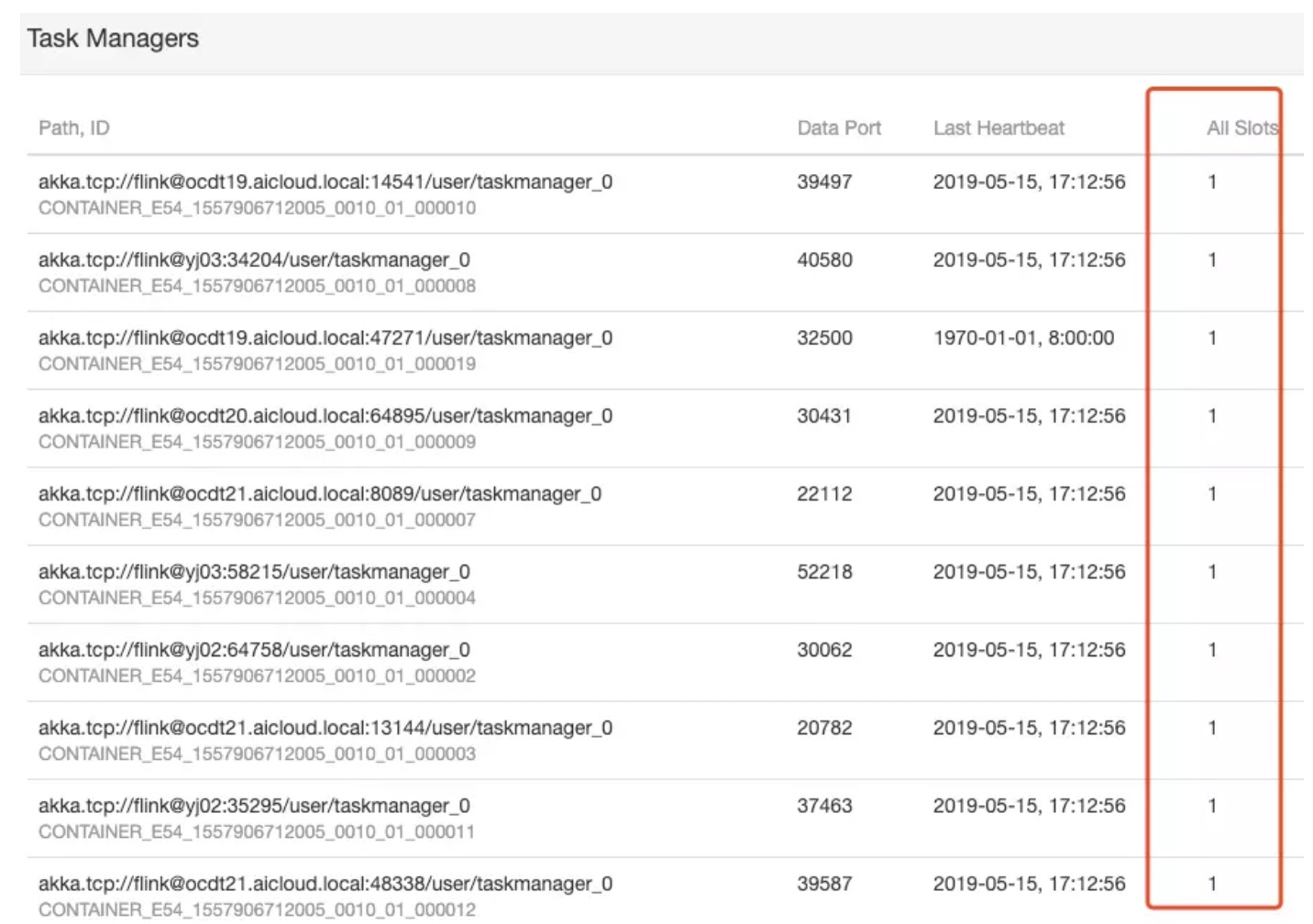
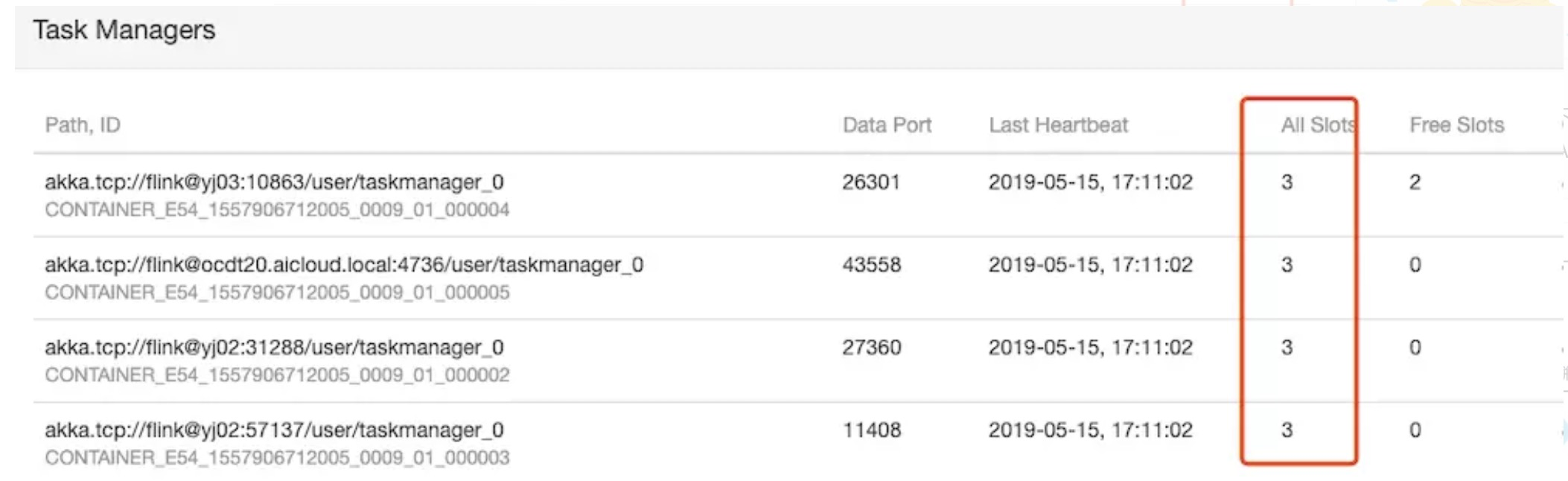
Flink Parallelism和Slots的关系
Slots决定了TaskManager的并发能力,Parallelism决定了TaskManager实际使用的并发能力,程序的并发度(Parallelism)不能超过TaskManager能提供的最大slots数量。
结合官网的示例进行解释:
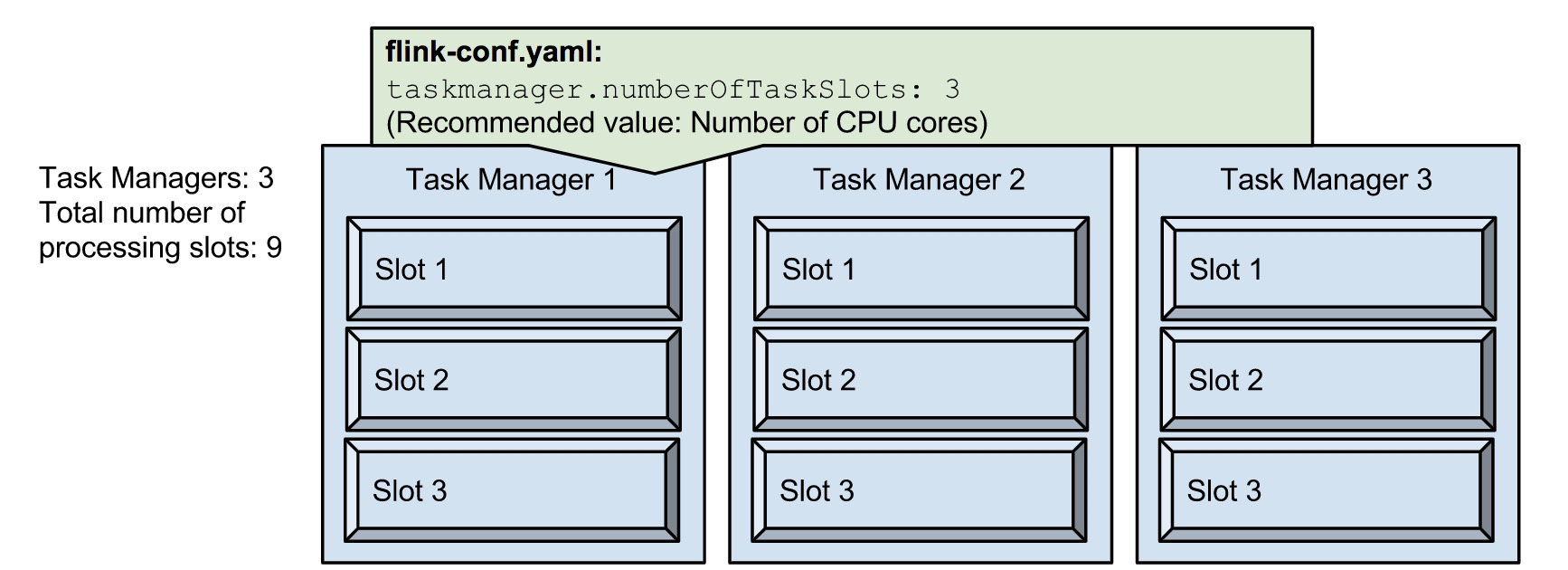
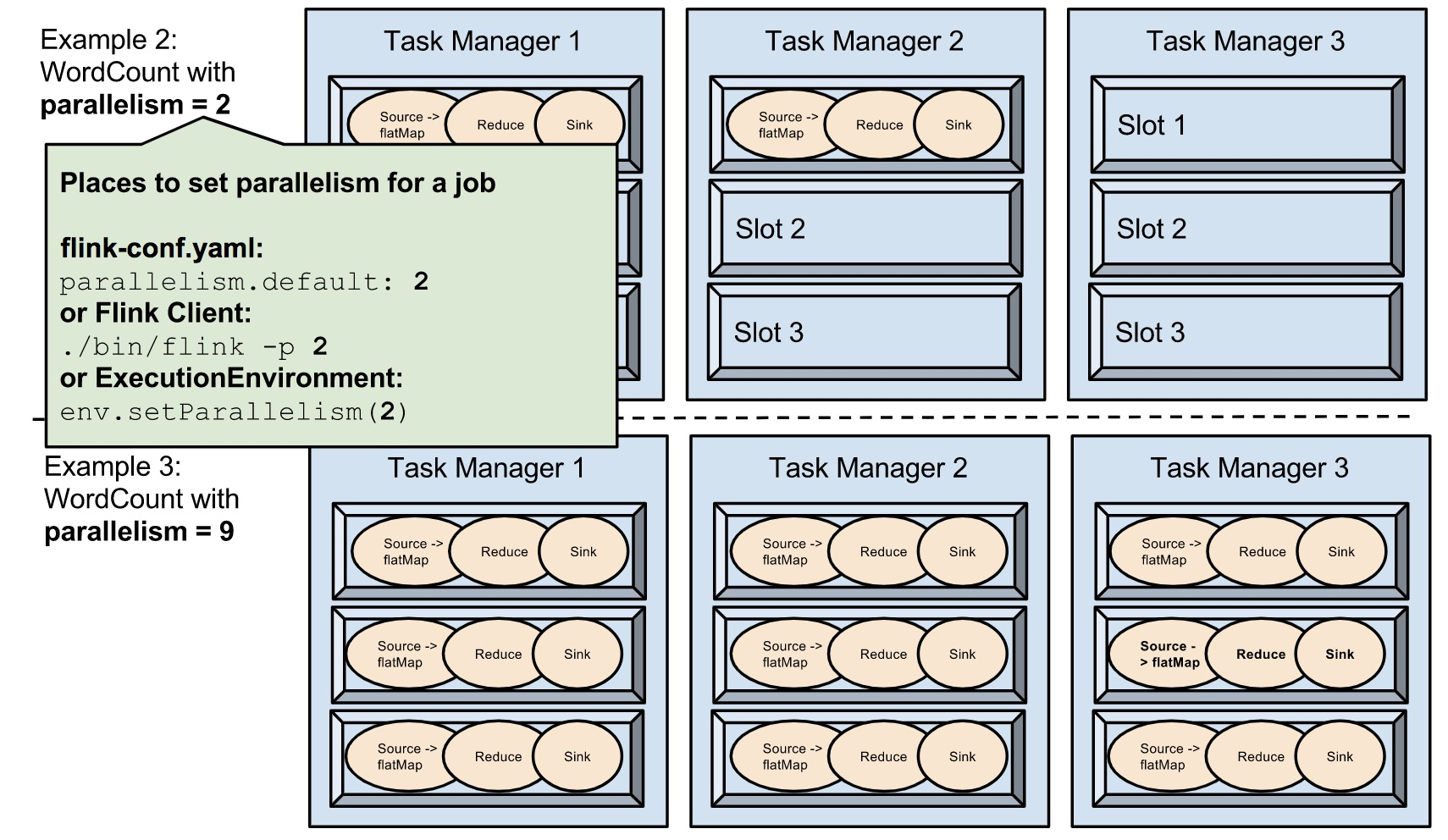
- taskmanager.numberOfTaskSlots:3 ,每个TaskManager分配3个TaskSlot,3个TaskManager一共9个TaskSlot。
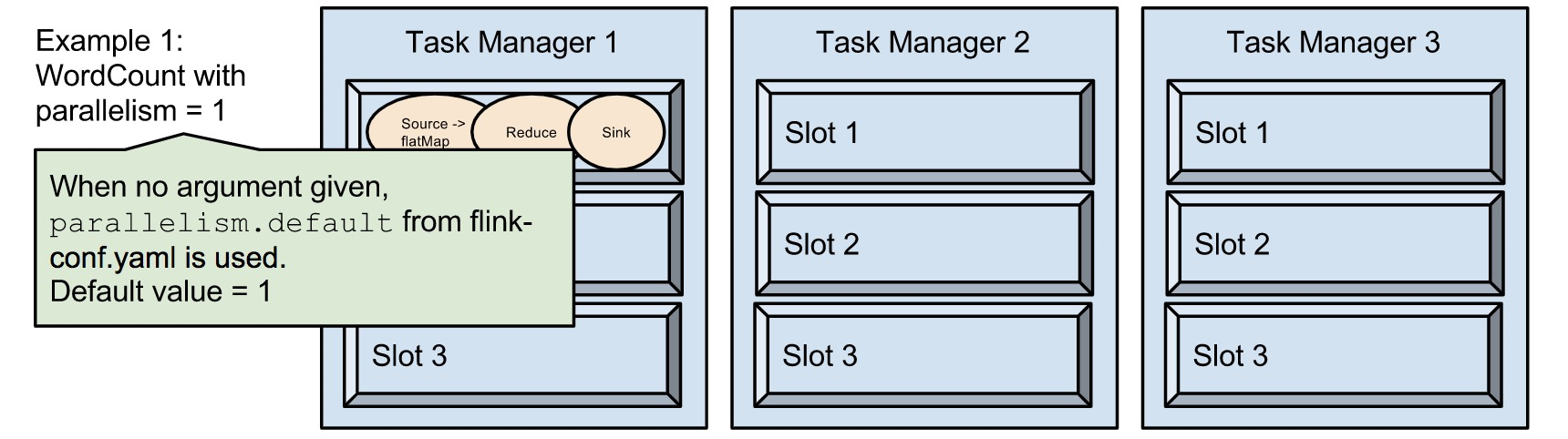
- parallelism:1,运行程序默认的并行度是1,9个TaskSlot只用了1个,8个是空闲。设置合适的并行度才能提高效率。
- 设置程序的并行度,parallelism:2
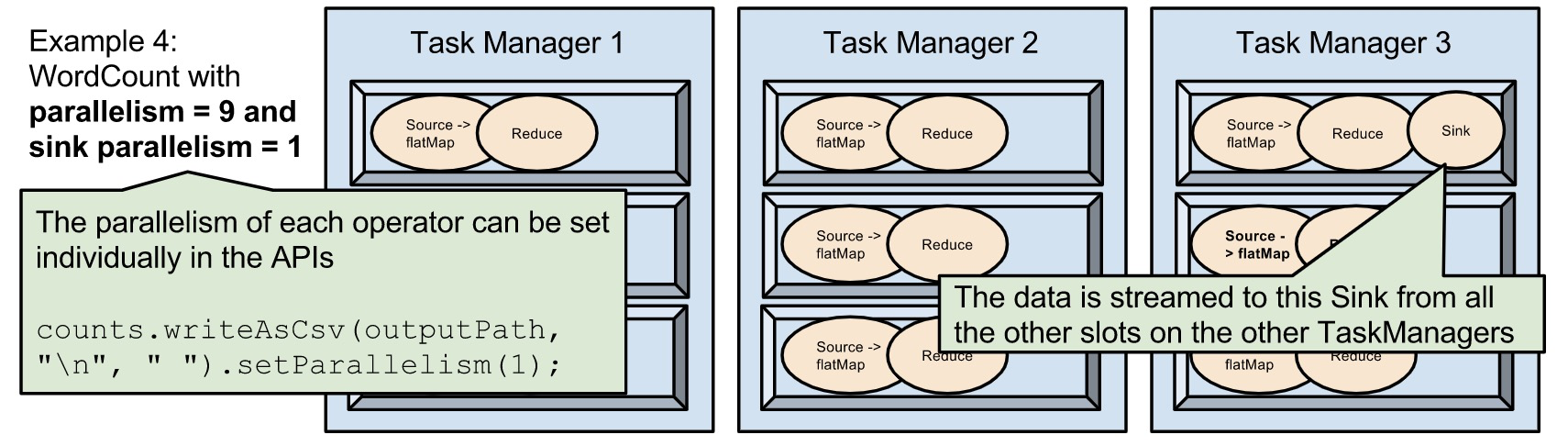
- 设置每个算子的并行度,除了sink的并行度为1,其他的算子的并行度都是9。
参考
文章作者 Hobbin
上次更新 2020-05-25 15:28:58