实时数仓模型
文章目录
实时数仓建模和离线建模非常类似,由于实时计算的局限性,每一层并没有像离线做的那么宽,维度和指标也没有那么多,特别是涉及回溯状态的指标,在实时数仓建模中基本没有。
整体来看,实时数仓是离线数仓的一个子集,在实时数据处理过程中,很多模型设计就是参考离线数据模型实现的。
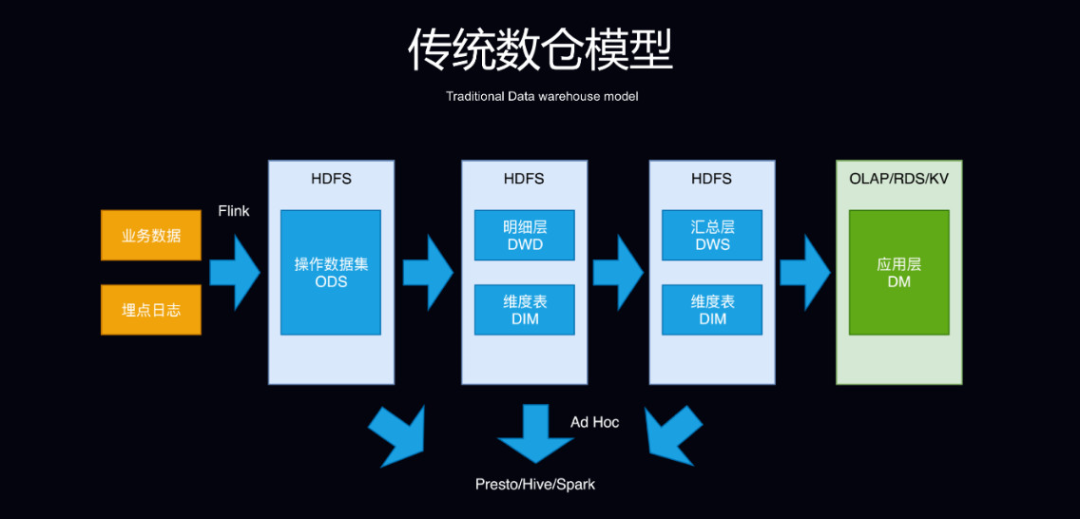
传统数仓模型和实时数仓模型的对比:
为了更有效地组织和管理数据,数仓建设往往会进行数据分层,一般自下而上分为四层:ODS(操作数据层)、DWD(数据明细层)、DWS(汇总层)和应用层。即时查询主要通过 Presto、Hive 和 Spark 实现。
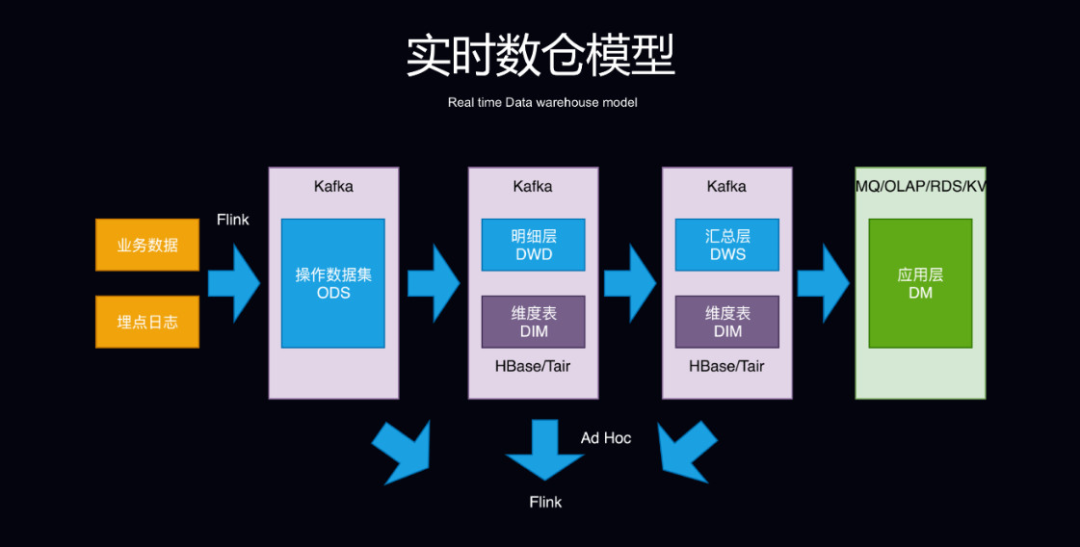
实时数仓的分层方式一般也遵守传统数据仓库模型,也分为了 ODS 操作数据集、DWD 明细层和 DWS 汇总层以及应用层。但实时数仓模型的处理的方式却和传统数仓有所差别,如明细层和汇总层的数据一般会放在 Kafka 上,维度数据一般考虑到性能问题则会放在 HBase 或者 Tair 等 KV 存储上,即席查询则可以使用 Flink 完成。
实时数仓分层架构
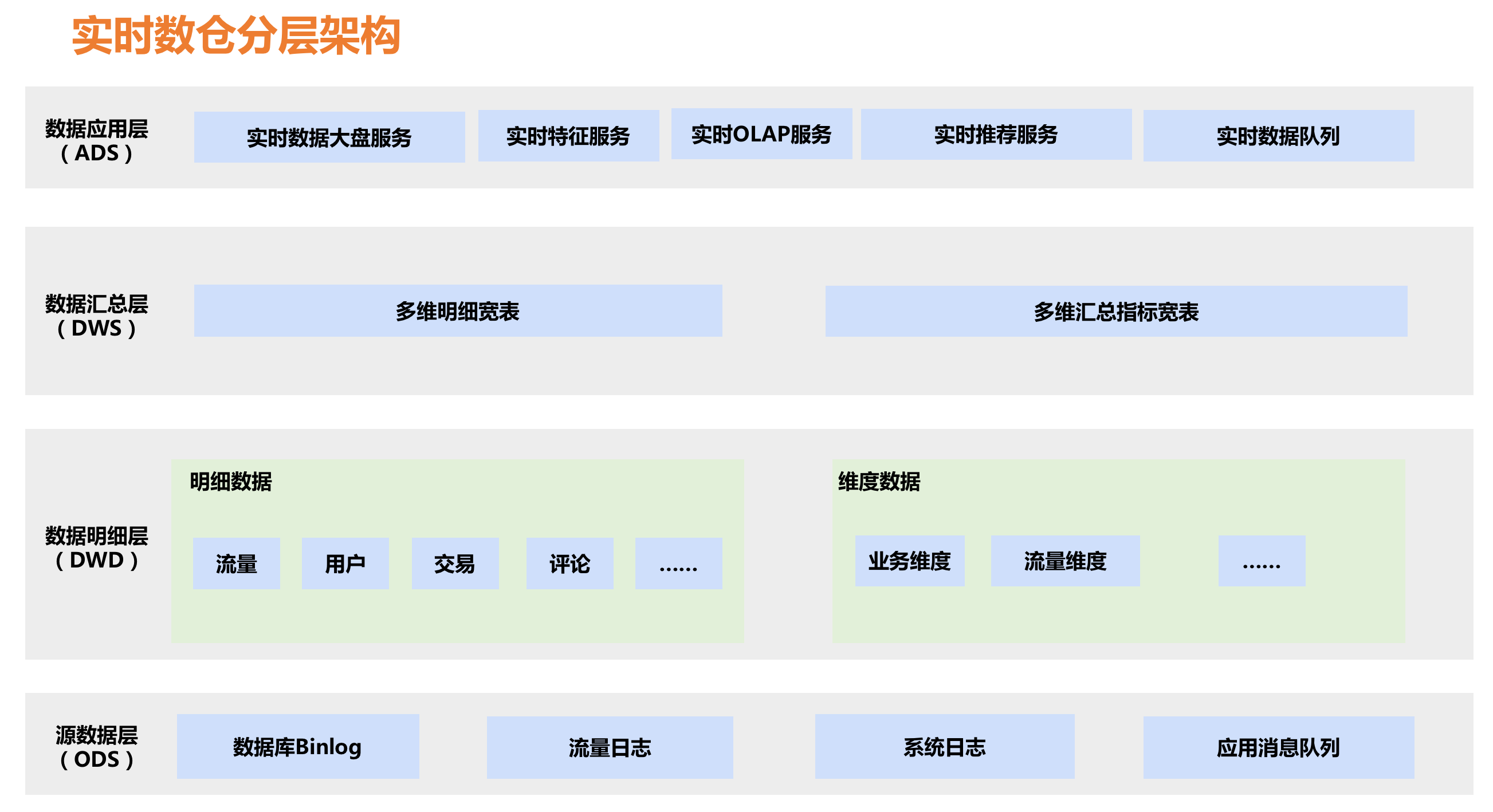
- ODS层
ODS层是操作数据层,是直接从业务采集过来的最原始的数据,包含了所有业务变更过程,数据粒度也是最细的。
- DSD层
在ODS层数据的基础上,根据业务过程建模出来的实时事实明细层。例如:订单的支付明细表、退款的明细表、用户的访问日志明细表等。
- DWS层
通用维度汇总层,该层的维度是各个垂直业务线通用的。订阅明细层的数据后,会在实时任务中计算各个维度的汇总指标。
- ADS层
个性化维度汇总层,对于不是特别通用的统计维度数据会放在这一层,这里计算只有自身业务才关注的维度和指标,与其他业务线没有交集。
下面通过一个例子来说明每一层存储的数据:
- ODS层:订单粒度的变更过程,一笔订单对应多条记录。
- DWD层:订单粒度的支付记录,一笔订单只有一条记录。
- DWS层:卖家的实时成交金额,一个卖家只有一条记录,并且指标在实时刷新
- ADS层:外卖地区的实时成交金额,只有外卖业务使用。
实时数仓存储方案

实时数仓计算引擎
| 引擎 | Flink | Spark Streaming | Storm |
|---|---|---|---|
| 处理模式 | 逐条流式处理 | 微批处理 | 逐条流式处理 |
| 延迟 | 毫秒级 | 秒级 | 毫秒级 |
| API | 流处理API、批处理API(后续会统一),以及开发成本更低的Table API和Flink SQL | 流处理API和Structured-Streaming API ,以及开发成本更低的Spark SQL | 灵活的底层API和具有事物保证的Trident API |
| 容错机制 | State、CheckPoint、SavePoint | RDD CheckPoint | ACK机制 |
| 语义保障 | Exactly Once,At Least Once | At Least Once | At Least Once,Exactly Once |
| 状态管理 | Key State 和 Operator State两种 State 可以使用,支持多种持久化方案 | 有 UpdateStateByKey 等 API 进行带状态的变更,支持多种持久化方案 | Trident State状态管理 |
多流关联
维表
- 事实表(fact table)和维表(dimension table)的概念
事实数据和维度数据通常需要依据具体的主题问题而定,事实表用来存储事实的度量及指向各个维的外键值,维表用来保存该维的元数据。
举个例子: 一个 “销售统计表” 就是一个事实表,而 “销售统计表” 里面统计数据的来源离不开 “商品价格表”,“商品价格表” 就是销售统计的一个维度表。事实数据和维度数据的识别必须依据具体的主题问题而定。
- 维表的使用
实时任务是常驻进程的,根据我们业务对维表数据关联的时效性要求,维表的使用有以下几种解决方案:
1)实时查询维表
实时查询维表是指用户在Flink 的Map算子中直接访问外部数据库,比如用 MySQL 来进行关联,这种方式是同步方式,数据保证是最新的。最后,为了保证连接及时关闭和释放,一定要在最后的 close 方式释放连接,否则会将 MySQL 的连接数打满导致任务失败。
一般我们在查询小数据量的维表情况下才使用这种方式,并且要妥善处理连接外部系统的线程,一般还会用到线程池。
2)预加载全量数据
在维表数据较少的情况下,可以一次性加载到内存中,在内存中直接和实时流数据进行关联,效率非常高。但缺点是内存一直占用着,并且需要定时更新。例如:类目维表,每天只有与几万条记录,在每天零点时全量加载到内存。适用于那些实时场景不是很高,维表数据较小的场景。
3)增量加载(LRU缓存)
维表数据很多,没办法全部加载到内存的时候,可以使用增量查找和LRU过期的形式,让最热的数据留在内存中。其优点是可以控制内存使用量,缺点是需要查找外部存储系统,运行效率会降低。例如,会员维表,会有上亿条记录,每次实时数据到达时,去外部数据库中查询,并把查询结果加载到内存中,然后每隔一段时间清理一次最近最少使用的数据,以避免内存溢出。
利用 Flink 的 RichAsyncFunction 读取 HBase 的数据到缓存中,我们在关联维度表时先去查询缓存,如果缓存中不存在这条数据,就利用客户端去查询 HBase,然后插入到缓存中。
4)将维表数据广播出去
|
|
在实际应用中,这几种形式根据维表数据量和实时性能要求综合考虑来选择使用。
参考
- 实时数仓-你想要的数仓分层设计与技术选型
- 深度解读实时数仓
- 美团实时数仓
- 《大数据之路 - 阿里巴巴大数据实践》
文章作者 Hobbin
上次更新 2021-03-01 13:40:45