分布式一致性算法
文章目录
分布式一致性算法:2PC、3PC、Paxos算法、Raft算法、Gossip算法。
2PC和3PC
2PC,二阶段提交协议,即将事务的提交过程分为两个阶段来进行处理:准备阶段和提交阶段。事务的发起者称协调者,事务的执行者称参与者。
3PC,三阶段提交协议,是2PC的改进版本,即将事务的提交过程分为CanCommit、PreCommit、do Commit三个阶段来进行处理。
Paxos算法
Paxos算法是分布式技术大师Lamport(也是拜占庭将军问题的提出者)在1990年提出的,主要目的是通过这个算法,让分布式处理的参与者逐步达成一致意见。简单地说,就是在一个选举过程中,让不同的选民做出最终一致的决定。
1.基本概念
- Proposer:提议的发起者
- Acceptor:提议的接受者
- Learner:提议学习者
- Proposal Value: 提议的值
- Proposal Number:提议的编号,要求提议编号不能冲突
- Proposal:提议 = 提议的值 + 提议的编号
2.Proposer有两个行为
- 向Acceptor发Prepare请求
- 向Acceptor发Accept请求
Acceptor根据协议规则,对Proposer的请求做出应答;
Learner根据Acceptor的状态,学习最终被确定的值。
3.约定
记{n, v} 为提议的编号为n,提议的值为v的提议;记{m, {n, v}}为承诺了Prepare(m)请求,并接受了提议{n, v}。
4.协议的过程
- 第一阶段A:Proposer选择一个提议编号n,向所有的Acceptor广播Prepare(n)请求;
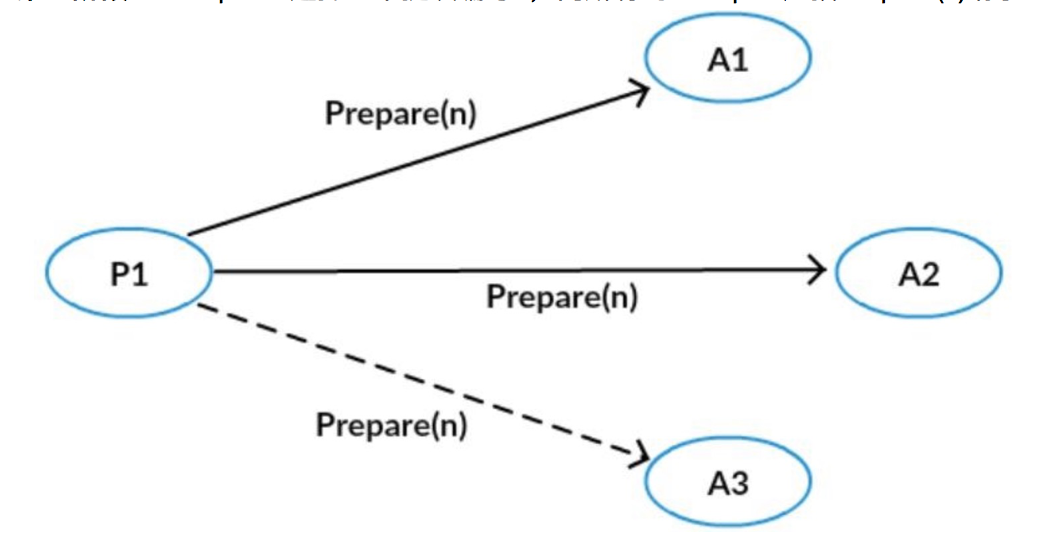
- 第一阶段B:Acceptor接收到Prepare(n)请求,若提议编号n比之前接受的Prepare编号都要大,则承诺不再接受比编号n小的提议;并且带上之前Accept的提议中编号比n小的最大提议。否则,不予理会。
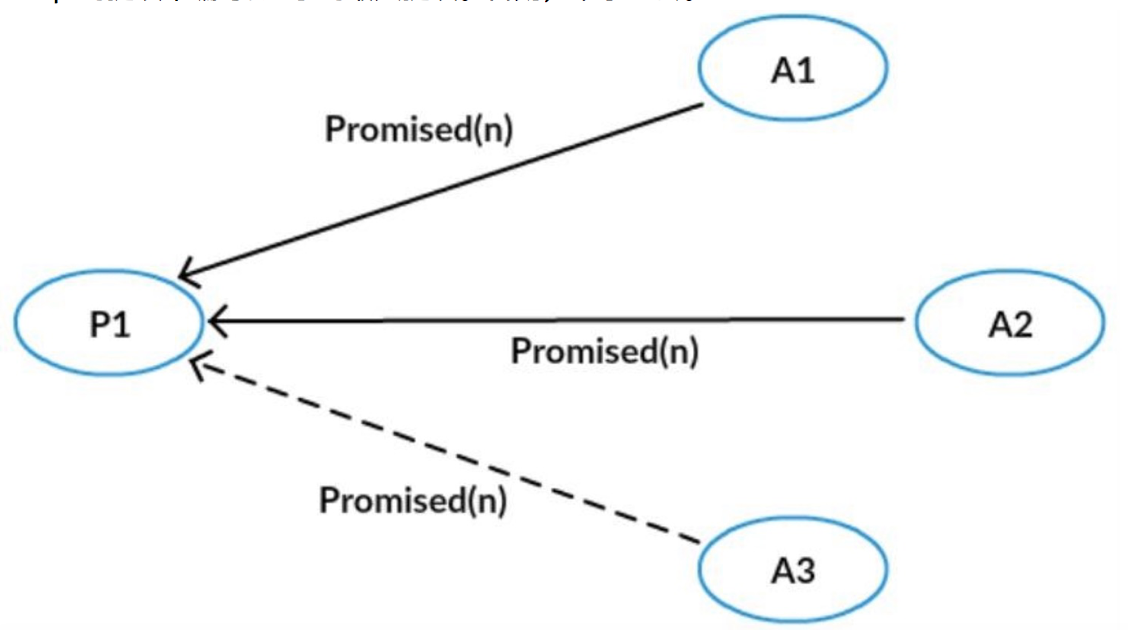
- 第二阶段A:Proposer接收到多数Acceptor的承诺后,如果Acceptor都没有接受过一个值,则向所有的Acceptor发起自己的值和提议编号n;否则,从所有的接受过的值中,选择对应的提议者编号最大的,作为提议的值,提议编号仍然为n。
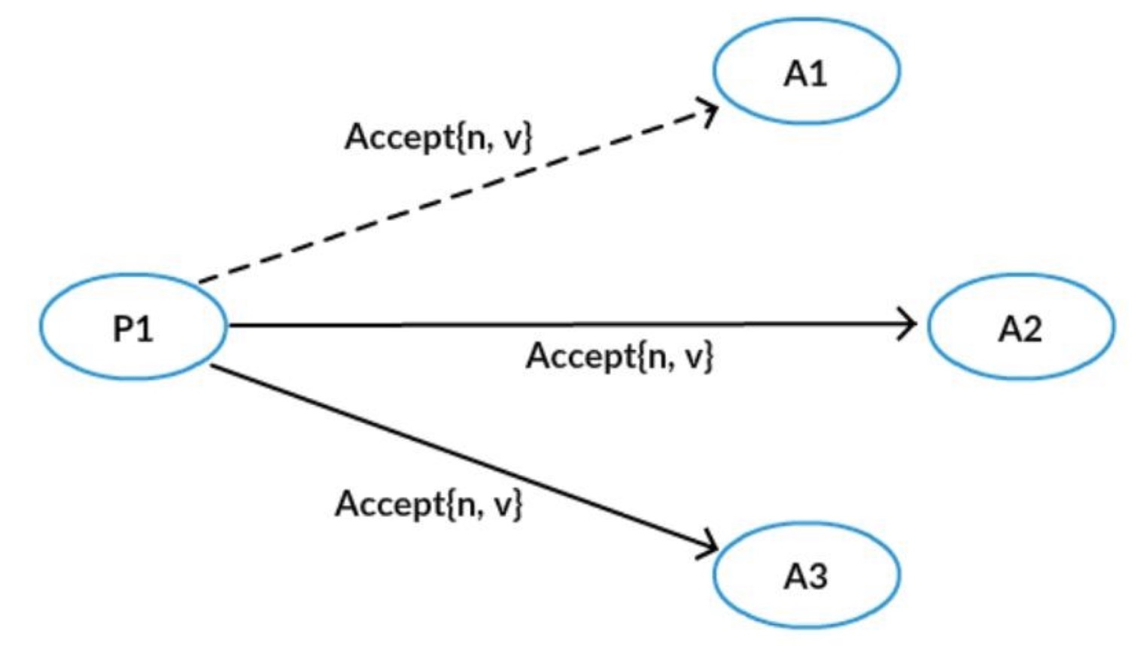
- 第二阶段B:Acceptor接收到提议后,如果该提议编号不违反自己做过的承诺,则接受该提议。
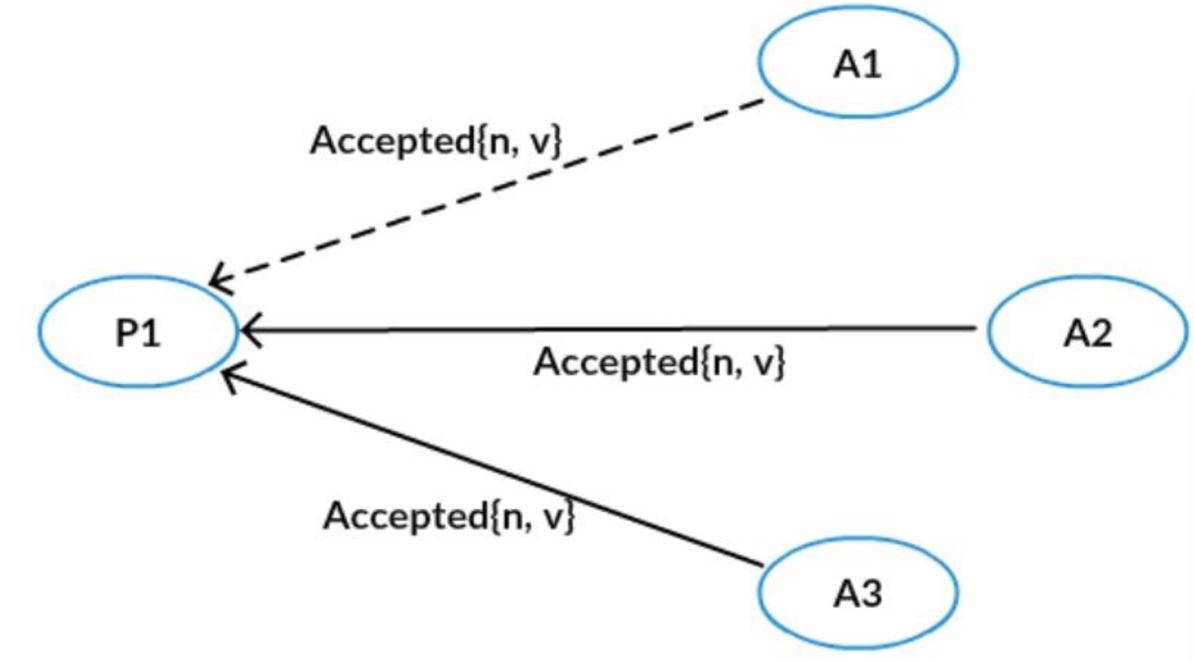
补充:
第一阶段B中,三个 Acceptor 之前都没有接受过 Accept 请求,所以不用返回接受过的提议,但是如果接受过提议,则根据第一阶段 B,要带上之前 Accept 的提议中编号小于 n 的最大的提议。
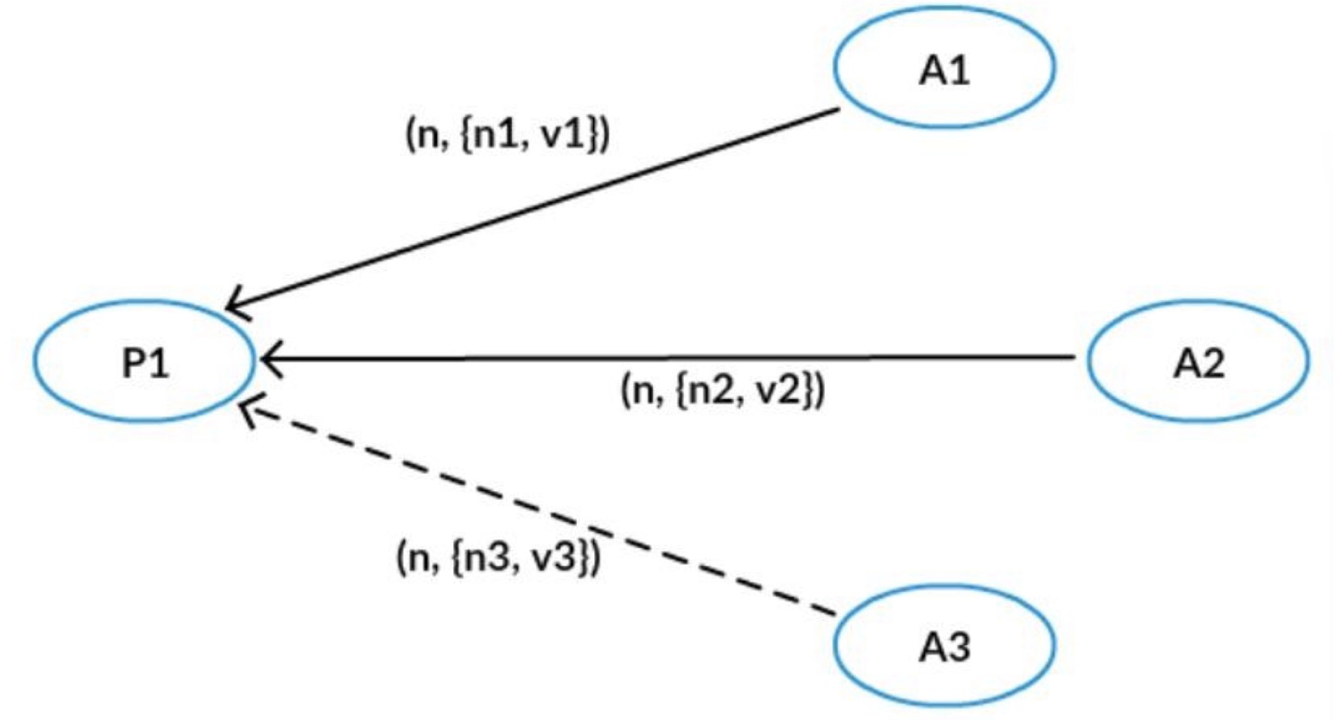
Proposer 广播 Prepare 请求之后,收到了 A1 和 A2 的应答,应答中携带了它们之前接受过的{n1, v1}和{n2, v2},Proposer 则根据 n1,n2 的大小关系,选择较大的那个提议对应的值,比如 n1 > n2,那么就选择 v1 作为提议的值,最后它向 Acceptor 广播提议{n, v1}。
5.Paxos 协议最终解决什么问题
当一个提议被多数派接受后,这个提议对应的值被 Chosen(选定),一旦有一个值被 Chosen,那么只要按照协议的规则继续交互,后续被 Chosen 的值都是同一个值,也就是这个 Chosen 值的一致性问题。
6.参考
Raft算法
因为Paxos难懂、难实现,斯坦福大学的教授在2014年发表了新的分布式一致性协议Raft。与Paxos相比,Raft协议有着基本相同的运行效率,但更容易理解,也更容易被应用在系统开发上。
1.基本概念
分布式系统中的每个节点有三种状态:Follower、Candidate、Leader,状态之间是可以相互转换的,参考下图。
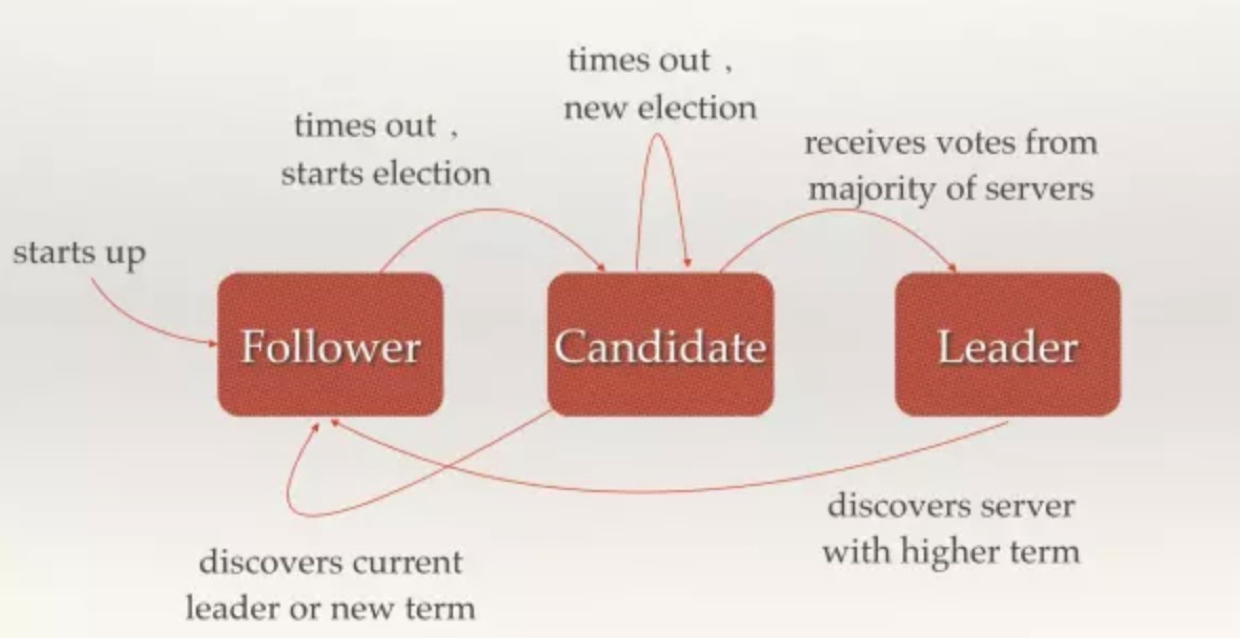
每个节点都有一个倒计时器(Election Timeout),时间随机在150ms和300ms之间。有几种情况会重设Timeout:1)收到选举的请求; 2)收到leader的HeartBeat。
在Raft运行过程中,最主要进行两个活动:1)选主Leader Election;2)复制日志,Log Replication。
2.选主Leader Election
1)正常情况下的选主
(1)5个节点,每个节点开始的状态都是Follower
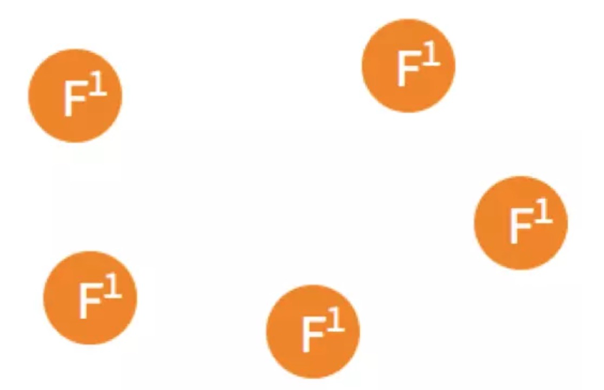
(2)在一个节点倒计时结束后,这个节点状态变成candidate,并给其他节点发送选举请求(RequestVote)
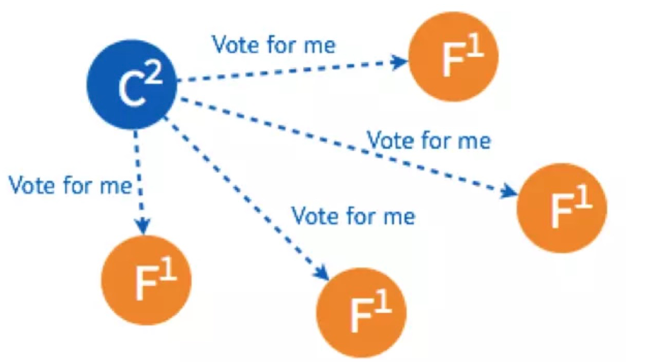
(3)其他几个节点都返回成功,则节点状态由candidate变成leader,并每隔一小段时间,给所有的Follower发送一个HeartBeat以保持所有节点的状态。Follower收到Leader的HeartBeat后重设Timeout
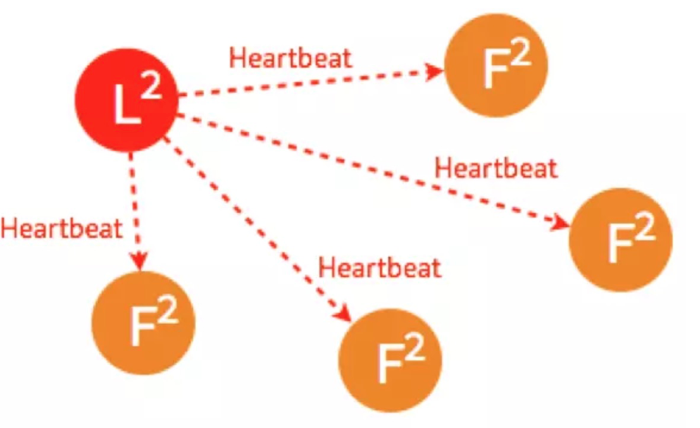
这是正常情况下,最简单的选主,只要有一半的节点投了支持票,candidate就可以选为leader,5个节点情况下,3个节点(包括candidate本身)投了就可以。 2)其他情况的选举,参考:共识算法:Raft
3.复制日志Log Replication
Raft一致性,更多的是表现在不同节点间数据的一致性,客户端发送请求到任何一个节点,都可以收到一致的返回。当一个节点出现故障后,其他节点仍能以已有的数据正常进行,在选主之后的复制日志就是为了达到这个目的。
1)正常情况下复制日志
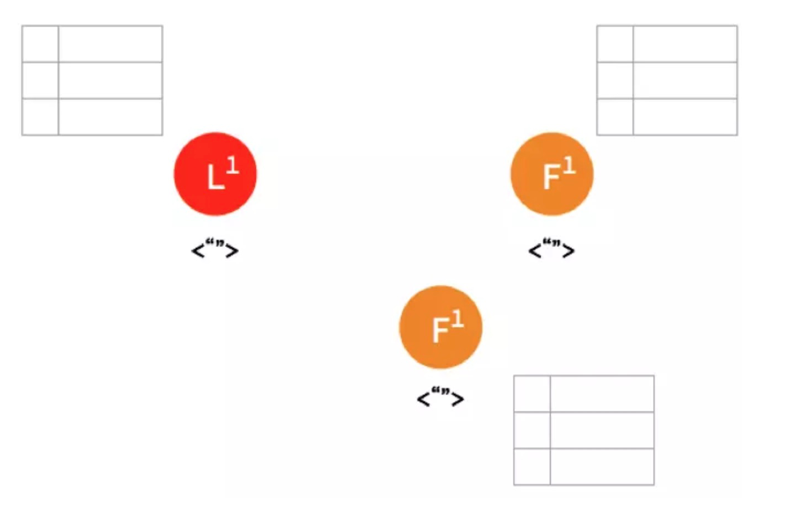
(1)一开始,Leader和Follower都没有任何数据。
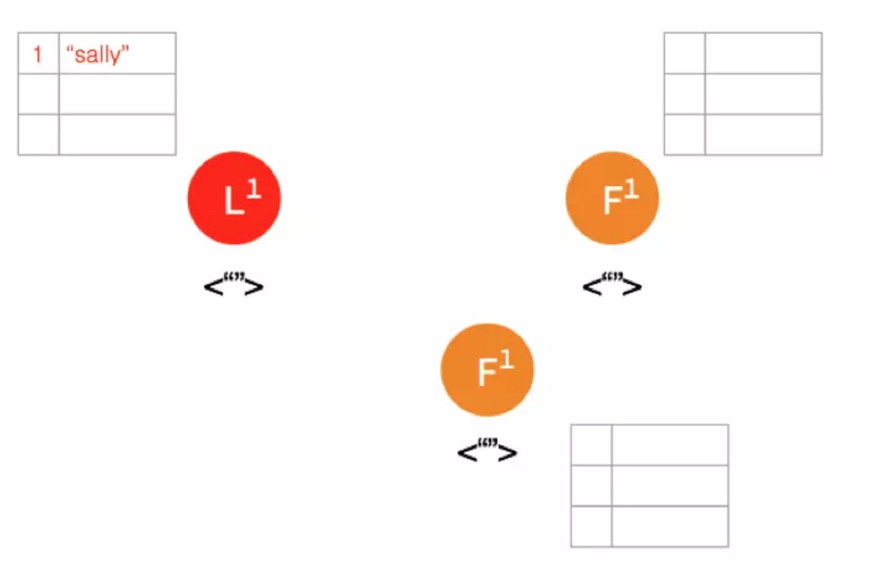
 (2)客户端发送请求给Leader,存储数据“Sally”,Leader先将数据保存到本地日志,这时候数据还是Uncommitted状态(红色代表还未确认)。
(2)客户端发送请求给Leader,存储数据“Sally”,Leader先将数据保存到本地日志,这时候数据还是Uncommitted状态(红色代表还未确认)。
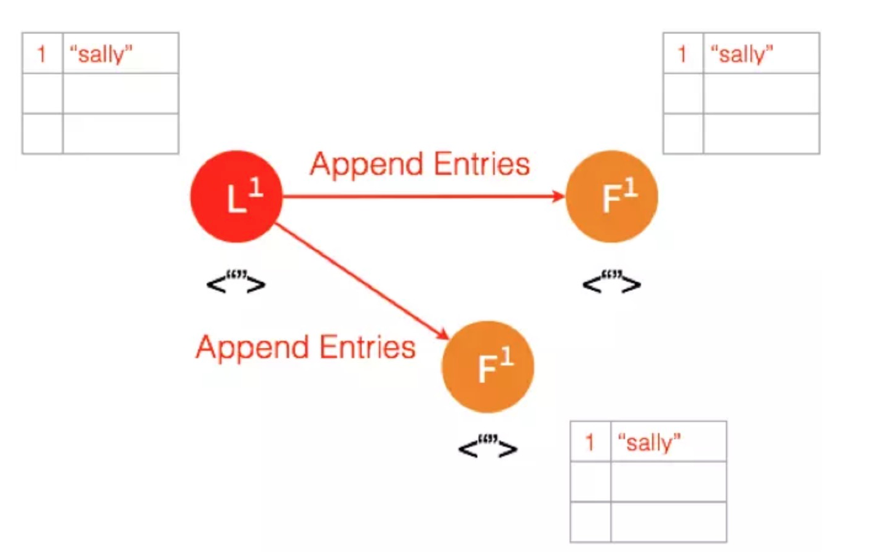
 (3)Leader给两个Follower发送AppendEntries请求,数据在Follower上没有冲突,则Follower先将数据放在本地日志,状态也是Uncommitted。
(3)Leader给两个Follower发送AppendEntries请求,数据在Follower上没有冲突,则Follower先将数据放在本地日志,状态也是Uncommitted。
 (4)Follower将数据写到本地后返回“ok”,Leader收到成功返回,只要收到成功的返回超过半数( 包括Leader本身),Leader将这条记录的状态更新成Commited(这时候Leader就可以返回给客户端了)。
(4)Follower将数据写到本地后返回“ok”,Leader收到成功返回,只要收到成功的返回超过半数( 包括Leader本身),Leader将这条记录的状态更新成Commited(这时候Leader就可以返回给客户端了)。
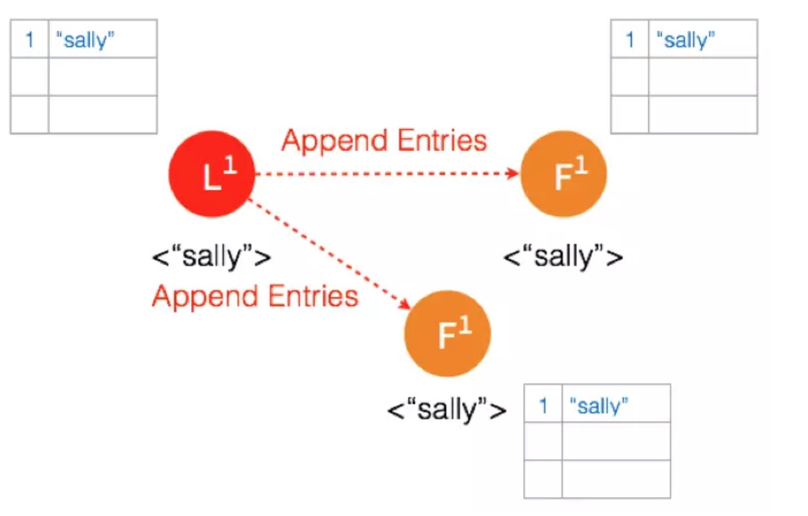
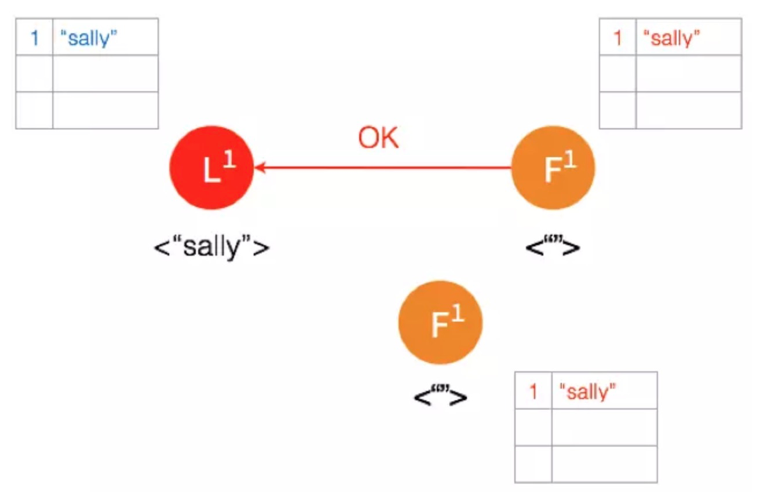 (5)Leader再次给Follower发送AppendEntries请求,Follower收到请求后将记录状态更新为Commited,完成日志复制过程。这样,三个节点的数据就是一致的。
(5)Leader再次给Follower发送AppendEntries请求,Follower收到请求后将记录状态更新为Commited,完成日志复制过程。这样,三个节点的数据就是一致的。
 2)Network Partition(由于网络故障,导致部分节点之间无法通信)情况下复制日志,参考:共识算法:Raft
2)Network Partition(由于网络故障,导致部分节点之间无法通信)情况下复制日志,参考:共识算法:Raft
4.Raft算法动画演示(推荐)
Gossip算法
参考
文章作者 Hobbin
上次更新 2020-06-18 21:59:47