关于批流一体
文章目录
流批一体的技术方案主要分为两种:1)跨引擎的流批一体,比如Flink和Spark组合使用,批交给Spark执行,流交给Flink执行;2)引擎本身就具备流批一体的能力,比如Spark和Spark Streaming、Flink等。
Flink 批流一体的两个层面:1)API层面的统一;2)Runtime层面的统一。
Flink是如何实现批处理的
实现批处理的技术有很多,从各种关系型数据库的sql处理,到大数据领域的MapReduce、Hive、Spark等,这些都是处理有限数据流的经典方式。Flink作为专注于无限流处理的计算引擎,是如何做到批处理的呢?
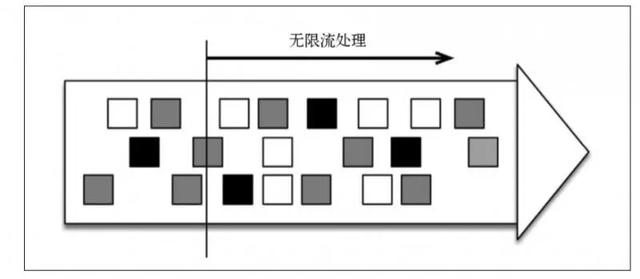
无限流处理:输入数据没有尽头,数据处理从当前或者过去的某个时间点开始,持续不停的进行。
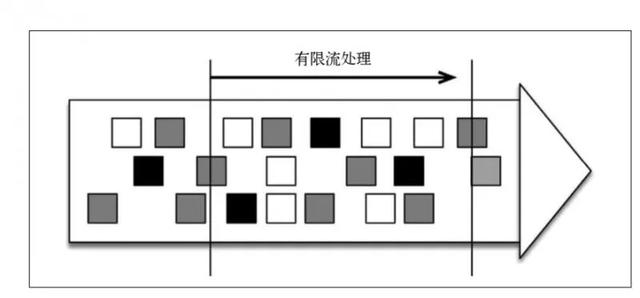
有限流处理:从某个时间点开始处理数据,然后在另一个时间点结束。输入数据可能本身是有限的(如输入数据集并不会随着时间增长),也可能处于分析目的被人为设定为有限集(即只分析某个时间段内的事件)。
显然,有限流处理是无限流处理的一种特殊情况。在流处理中,为数据定义滑动窗口或者滚动窗口,并且在每次窗口滑动或者滚动时生成结果。批处理则不同,我们定义一个全局窗口,所有的记录都属于同一个窗口。
示例:
- 每小时对网站的访问者计数,并按照地区分组
|
|
- 如果知道输入数据是有限的,则可以使用全局窗口实现批处理
|
|
- Flink即可以将数据作为无限流来处理,也可以将数据作为有限流来处理,Flink的DataSet API就是为批处理而生的。用DataSet API实现访问者统计代码如下。
|
|
如果输入数据是有限的,则该代码的运行结果与前面的代码是相同的,但是它对习惯于批处理器的程序员更友好一些。
Flink的批处理模型:
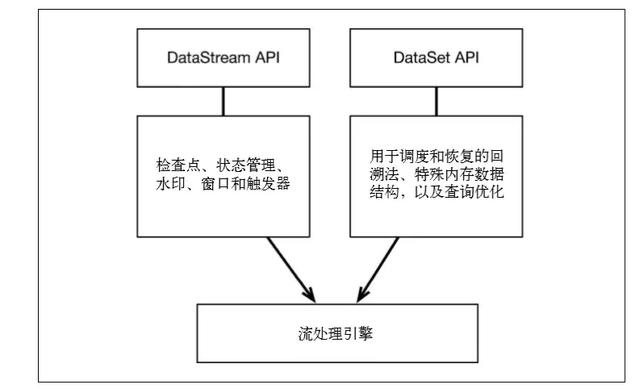
在流处理引擎之上,Flink有以下机制:
-
检查点机制和状态机制:用于实现容错、有状态的处理
-
水印机制:用于实现事件时钟
-
窗口和触发器:用于限制计算范围,并定义呈现结果的时间
在同一个流处理引擎之上,Flink 还存在另一套机制,用于实现高效的批处理。
-
用于调度和恢复的回溯法:由 Microsoft Dryad 引入,现在几乎用于所有批处理器
-
用于散列和排序的特殊内存数据结构:可以在需要时,将一部分数据从内存溢出到硬盘上
-
优化器:尽可能地缩短生成结果的时间
两套机制分别对应各自的API(DataStream API 和 DataSet API),在创建Flink作业时,并不能通过将两者混合在一起来同时利用 Flink 的所有功能。
Flink SQL实现批流统一
从1.9版本开始,Flink SQL作为用户使用的最主流API,率先实现了流批一体语义,用户只需学习使用一套SQL就可以基于Flink进行流批一体的开发,降低了开发门槛。
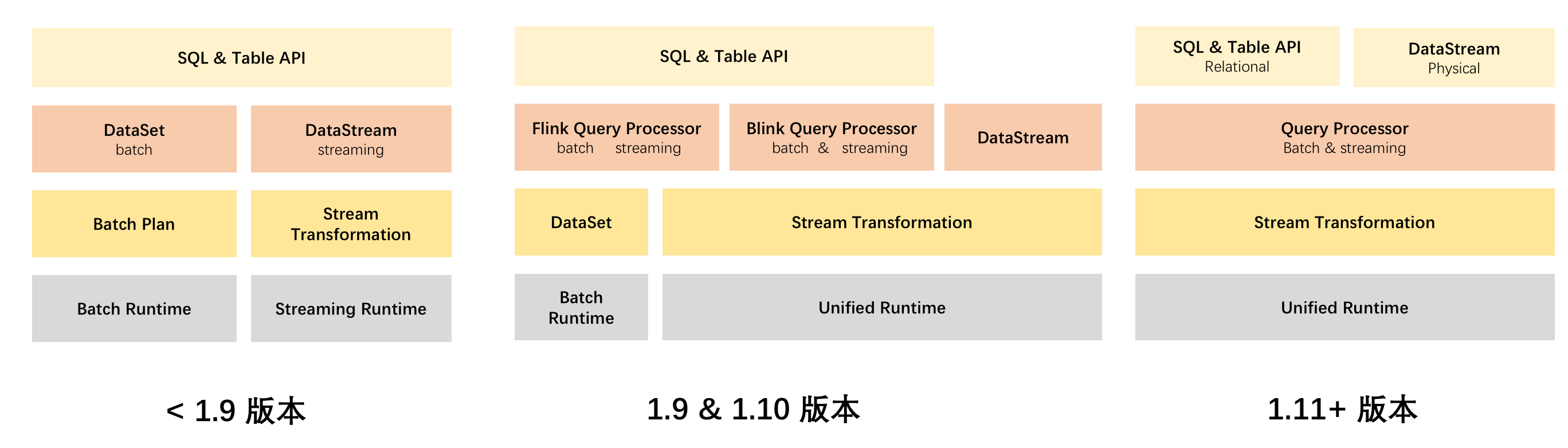
最初SQL实现批流一体的做法是将流作业和批作业分别翻译成Flink底层的两个原生API,包括处理流计算需求的DataStream和处理批计算需求的DatasSet ,相对简单粗暴。引来的问题包括开发链路过长导致迭代效率不高等。
针对这个问题,Flink社区又对底层架构做了一些重构,并引入了DAG API,Flink分布式运行层针对DAG做了一系列优化,包括增加批流一体调度器、可插拔的Shuffle插件等。这样一来,Flink的分布式运行层也开始逐渐形成了流批一体的DAG描述能力和调度执行能力。
Flink DataStream API实现流批一体
虽然开发者已经可以方便地基于SQL API执行流批一体的作业,但SQL并不能解决所有需求。一些逻辑特别复杂或者定制化程度比较高的作用也还是需要使用DataStream API。DataStream API虽然能更加灵活地应对流计算场景的各种需求,但缺乏对批处理的高效支持。因此Flink社区在完成SQL流批一体升级之后,从1.11版本开始投入大量精力完善DataStream API的流批一体能力。在 DataSteam API 上增加批处理的语义,同时结合流批一体 Connector 的设计,让 DataStream API 能够在流批融合场景下对接 Kafka 和 HDFS 等不同类型流批数据源。
参考
文章作者 Hobbin
上次更新 2021-05-20 21:22:08