文档型数据库、列数据库和图数据库分析
对比常用文档型数据库,如ElasticSearch、MongoDB,图数据库,如JanusGraph、Neo4J等。 ElasticSearch 数据模型:文档型数据库
实时数仓建模和离线建模非常类似,由于实时计算的局限性,每一层并没有像离线做的那么宽,维度和指标也没有那么多,特别是涉及回溯状态的指标,在实时数仓建模中基本没有。
整体来看,实时数仓是离线数仓的一个子集,在实时数据处理过程中,很多模型设计就是参考离线数据模型实现的。
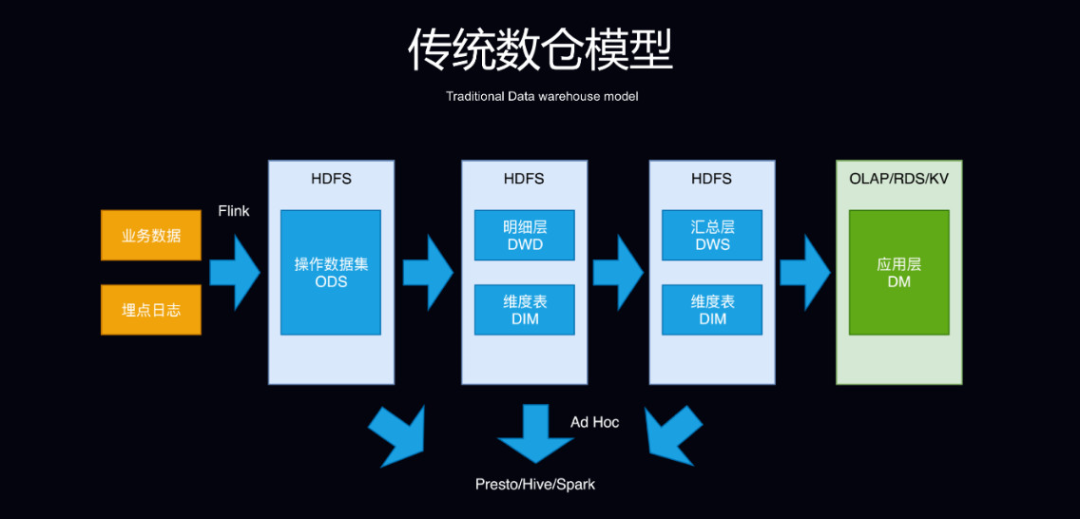
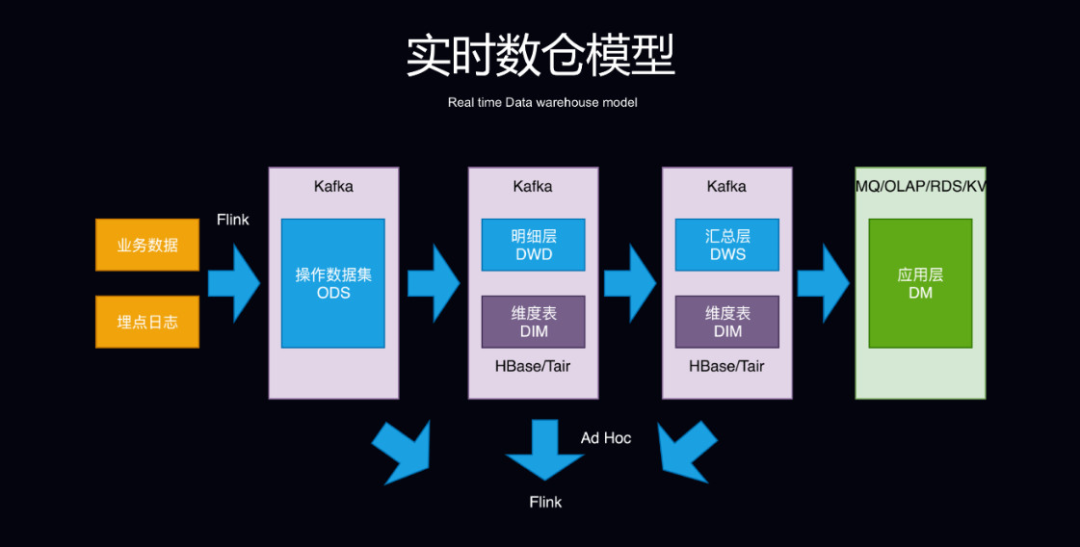
传统数仓模型和实时数仓模型的对比:
为了更有效地组织和管理数据,数仓建设往往会进行数据分层,一般自下而上分为四层:ODS(操作数据层)、DWD(数据明细层)、DWS(汇总层)和应用层。即时查询主要通过 Presto、Hive 和 Spark 实现。
实时数仓的分层方式一般也遵守传统数据仓库模型,也分为了 ODS 操作数据集、DWD 明细层和 DWS 汇总层以及应用层。但实时数仓模型的处理的方式却和传统数仓有所差别,如明细层和汇总层的数据一般会放在 Kafka 上,维度数据一般考虑到性能问题则会放在 HBase 或者 Tair 等 KV 存储上,即席查询则可以使用 Flink 完成。
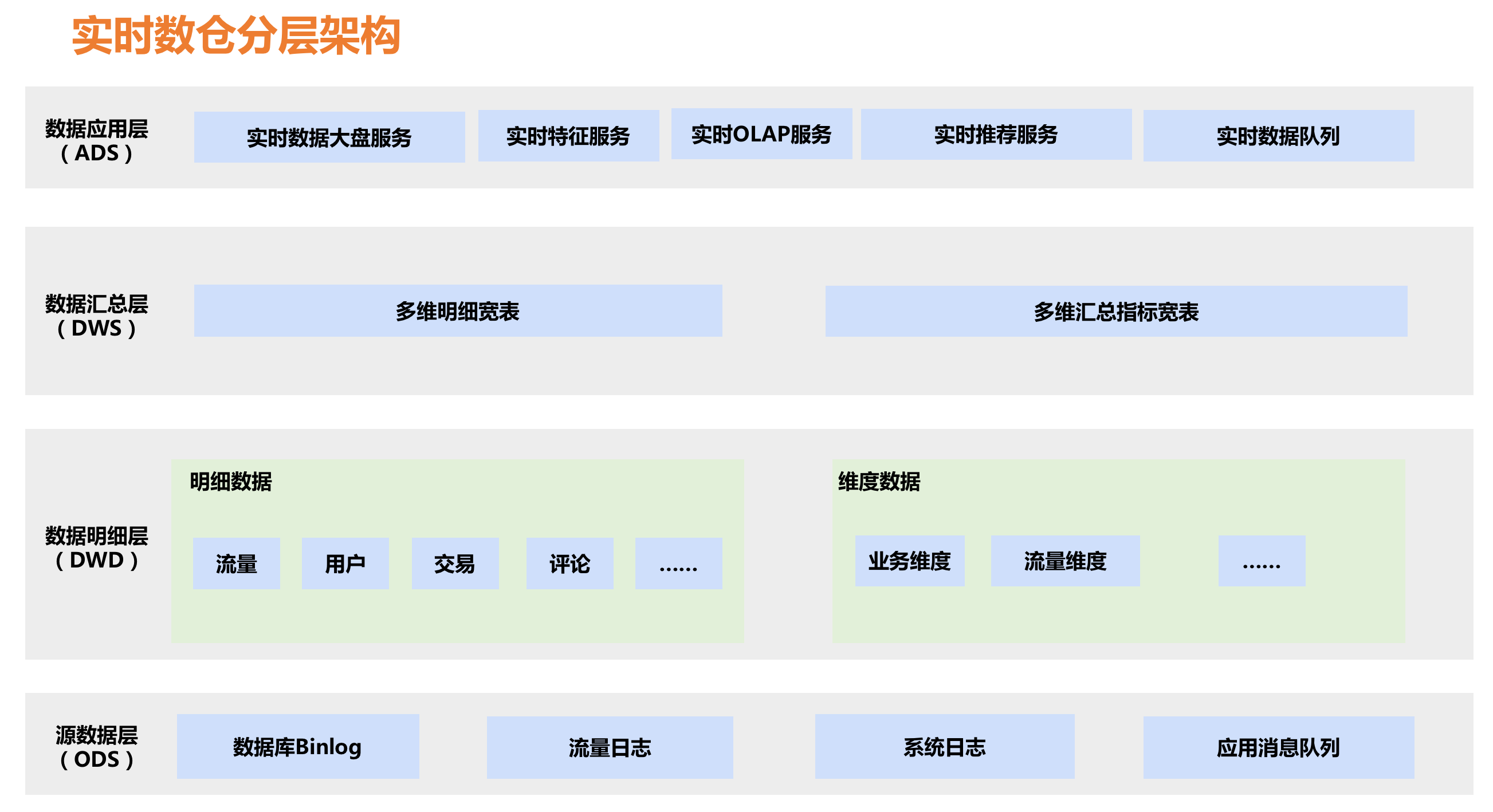
ODS层是操作数据层,是直接从业务采集过来的最原始的数据,包含了所有业务变更过程,数据粒度也是最细的。
在ODS层数据的基础上,根据业务过程建模出来的实时事实明细层。例如:订单的支付明细表、退款的明细表、用户的访问日志明细表等。
通用维度汇总层,该层的维度是各个垂直业务线通用的。订阅明细层的数据后,会在实时任务中计算各个维度的汇总指标。
个性化维度汇总层,对于不是特别通用的统计维度数据会放在这一层,这里计算只有自身业务才关注的维度和指标,与其他业务线没有交集。
下面通过一个例子来说明每一层存储的数据:

| 引擎 | Flink | Spark Streaming | Storm |
|---|---|---|---|
| 处理模式 | 逐条流式处理 | 微批处理 | 逐条流式处理 |
| 延迟 | 毫秒级 | 秒级 | 毫秒级 |
| API | 流处理API、批处理API(后续会统一),以及开发成本更低的Table API和Flink SQL | 流处理API和Structured-Streaming API ,以及开发成本更低的Spark SQL | 灵活的底层API和具有事物保证的Trident API |
| 容错机制 | State、CheckPoint、SavePoint | RDD CheckPoint | ACK机制 |
| 语义保障 | Exactly Once,At Least Once | At Least Once | At Least Once,Exactly Once |
| 状态管理 | Key State 和 Operator State两种 State 可以使用,支持多种持久化方案 | 有 UpdateStateByKey 等 API 进行带状态的变更,支持多种持久化方案 | Trident State状态管理 |